Lendo texto da imagem
Alguma sugestão para converter essas imagens em texto? Estou usando pytesseract e está funcionando maravilhosamente na maioria dos casos, exceto isso. Idealmente, eu li esses números exatamente. No pior caso, posso apenas tentar usar o PIL para determinar se o número à esquerda do '/' é zero. Comece pela esquerda e encontre o primeiro pixel branco, depois


from PIL import Image
from pytesseract import image_to_string
myText = image_to_string(Image.open("tmp/test.jpg"),config='-psm 10')
myText = image_to_string(Image.open("tmp/test.jpg"))
A barra no meio causa problemas aqui. Também tentei usar o '.paste' do PIL para adicionar muito preto extra à imagem. Pode haver alguns outros truques do PIL que eu poderia tentar, mas prefiro não seguir esse caminho, a menos que precise.
Eu tentei usar config = '- psm 10', mas meus 8 estavam chegando como ":" às vezes, e caracteres aleatórios outras vezes. E meus 0 estavam chegando como nada.
Referência a:pytesseract não funciona com uma imagem de um dígito para o -psm 10
_____________EDITAR_______________ Amostras adicionais:



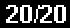
Então, eu estou fazendo algumas conversões de vodu que parecem estar funcionando por enquanto. Mas parece muito propenso a erros:
def ConvertPPTextToReadableNumbers(text):
text = RemoveNonASCIICharacters(text)
text = text.replace("I]", "0")
text = text.replace("|]", "0")
text = text.replace("l]", "0")
text = text.replace("B", "8")
text = text.replace("D", "0")
text = text.replace("S", "5")
text = text.replace(".I'", "/")
text = text.replace(".I", "/")
text = text.replace("I'", "/")
text = text.replace("J", "/")
return text
Em última análise, gera:
ConvertPPTextToReadableNumbers return text = 18/20
ConvertPPTextToReadableNumbers return text = 0/5
ConvertPPTextToReadableNumbers return text = 10/10
ConvertPPTextToReadableNumbers return text = 20/20