O valor de groupby conta com os pandas do dataframe
Eu tenho o seguinte quadro de dados:
df = pd.DataFrame([
(1, 1, 'term1'),
(1, 2, 'term2'),
(1, 1, 'term1'),
(1, 1, 'term2'),
(2, 2, 'term3'),
(2, 3, 'term1'),
(2, 2, 'term1')
], columns=['id', 'group', 'term'])
Quero agrupar porid egroup e calcule o número de cada termo para esse ID, par de grupos.
Então, no final, eu vou conseguir algo assim:
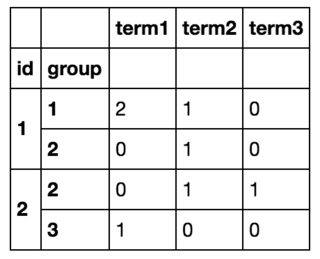
Consegui alcançar o que queria fazendo um loop por todas as linhas comdf.iterrows() e criar um novo quadro de dados, mas isso é claramente ineficiente. (Se ajudar, conheço a lista de todos os termos de antemão e existem ~ 10 deles).
Parece que eu tenho que agrupar e contar valores, então tentei isso comdf.groupby(['id', 'group']).value_counts() o que não funciona porquevalue_counts opera na série groupby e não em um dataframe.
Enfim, eu posso conseguir isso sem loop?