Spark :: o KMeans chama takeSample () duas vezes?
Eu tenho muitos dados e experimentei partições de cardinalidade [20k, 200k +].
Eu chamo assim:
from pyspark.mllib.clustering import KMeans, KMeansModel
C0 = KMeans.train(first, 8192, initializationMode='random', maxIterations=10, seed=None)
C0 = KMeans.train(second, 8192, initializationMode='random', maxIterations=10, seed=None)
e eu vejo issoinitRandom () chamadastakeSample() uma vez.
Então otakeSample () implementação parece não se chamar ou algo assim, então eu esperariaKMeans() chamartakeSample() uma vez. Então, por que o monitor mostra doistakeSample()s porKMeans()?
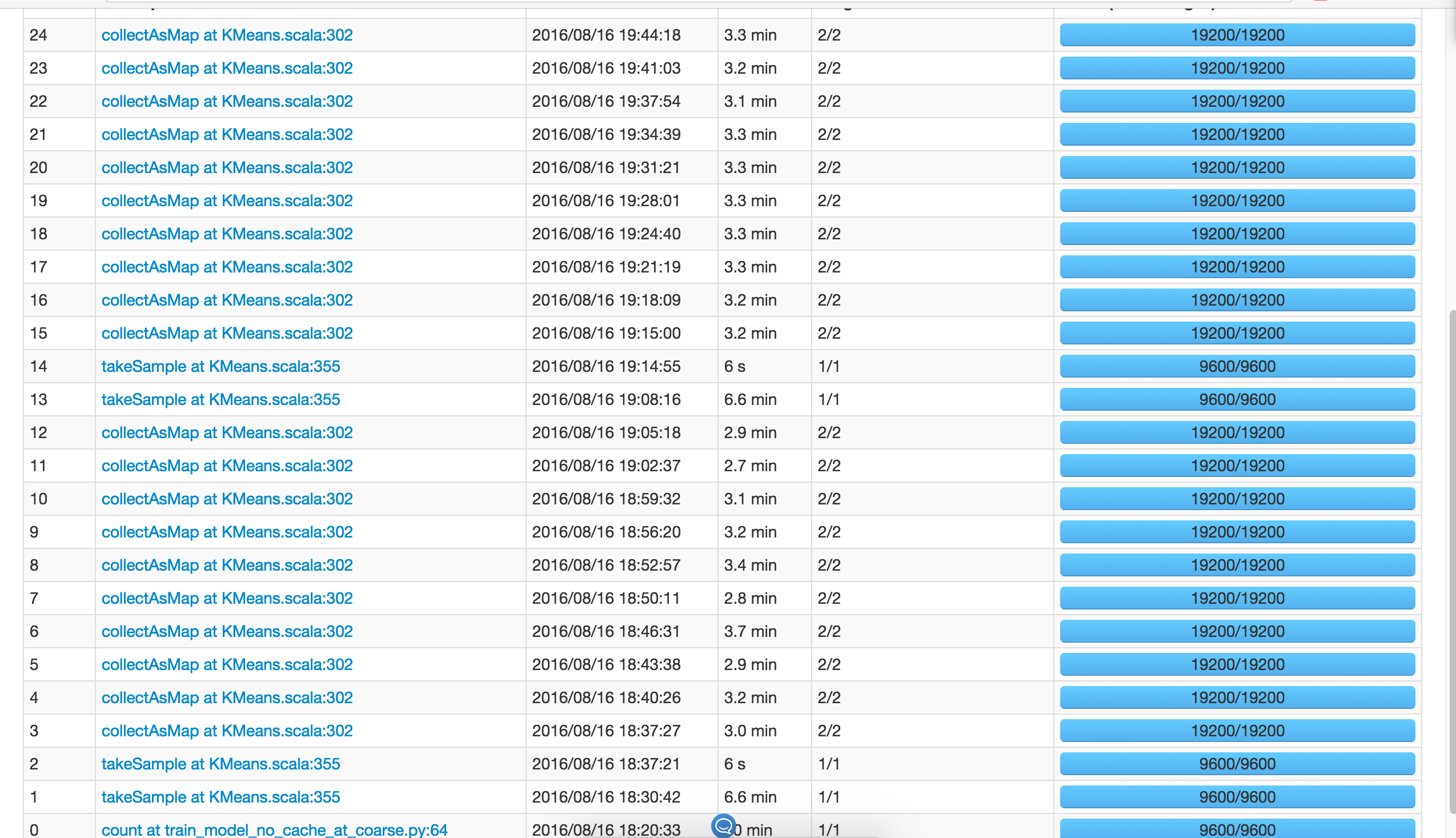
Nota: eu executo maisKMeans() e todos invocam doistakeSample()s, independentemente dos dados que estão sendo.cache()ou não.
Além disso, o número de partições não afeta o númerotakeSample() é chamado, é constante para 2.
Estou usando o Spark 1.6.2 (e não posso atualizar) e meu aplicativo está em Python, se isso importa!
Trouxe isso para a lista de discussão dos desenvolvedores do Spark, por isso estou atualizando:
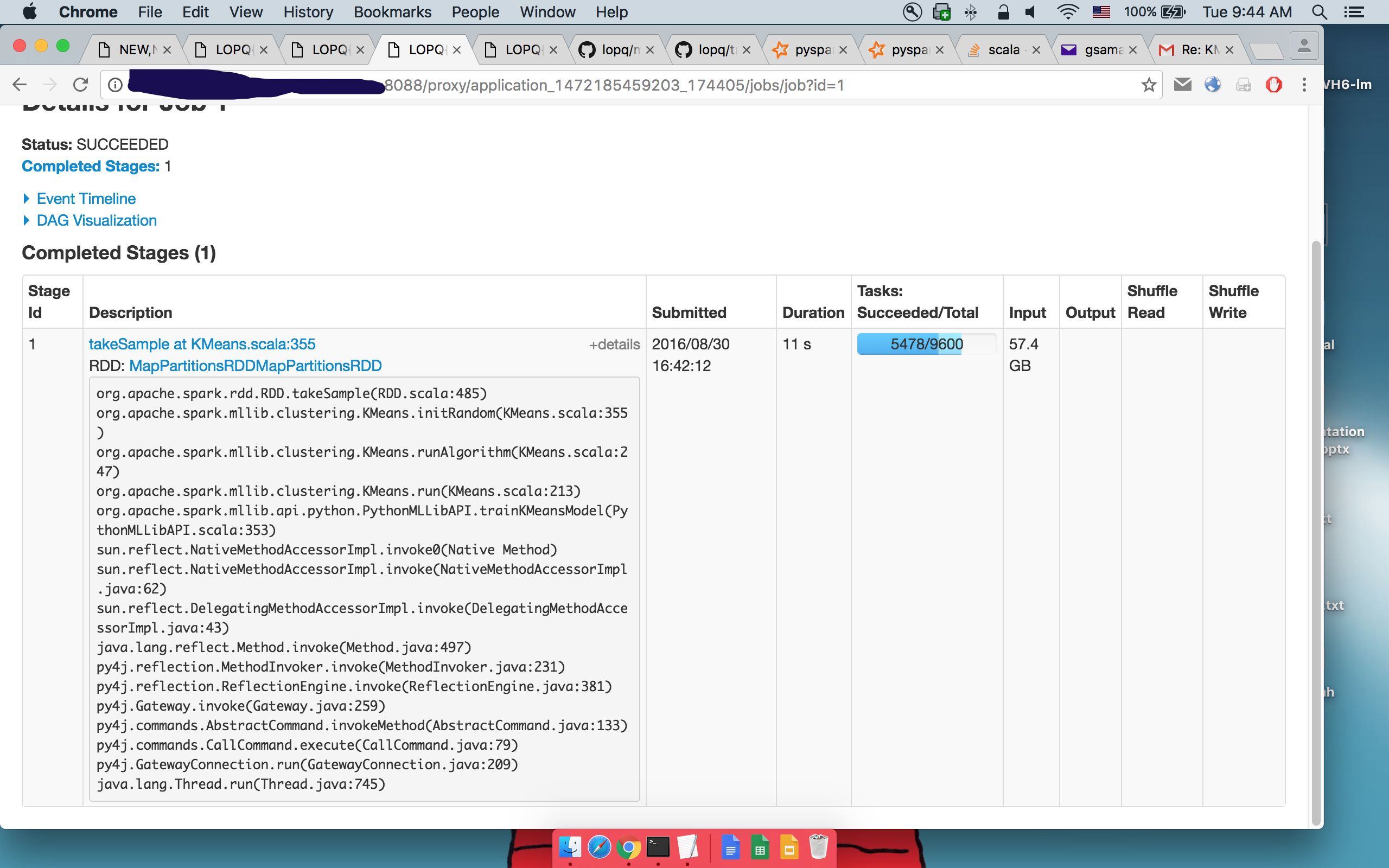
Detalhes do 1ºtakeSample():
Detalhes do 2ºtakeSample():
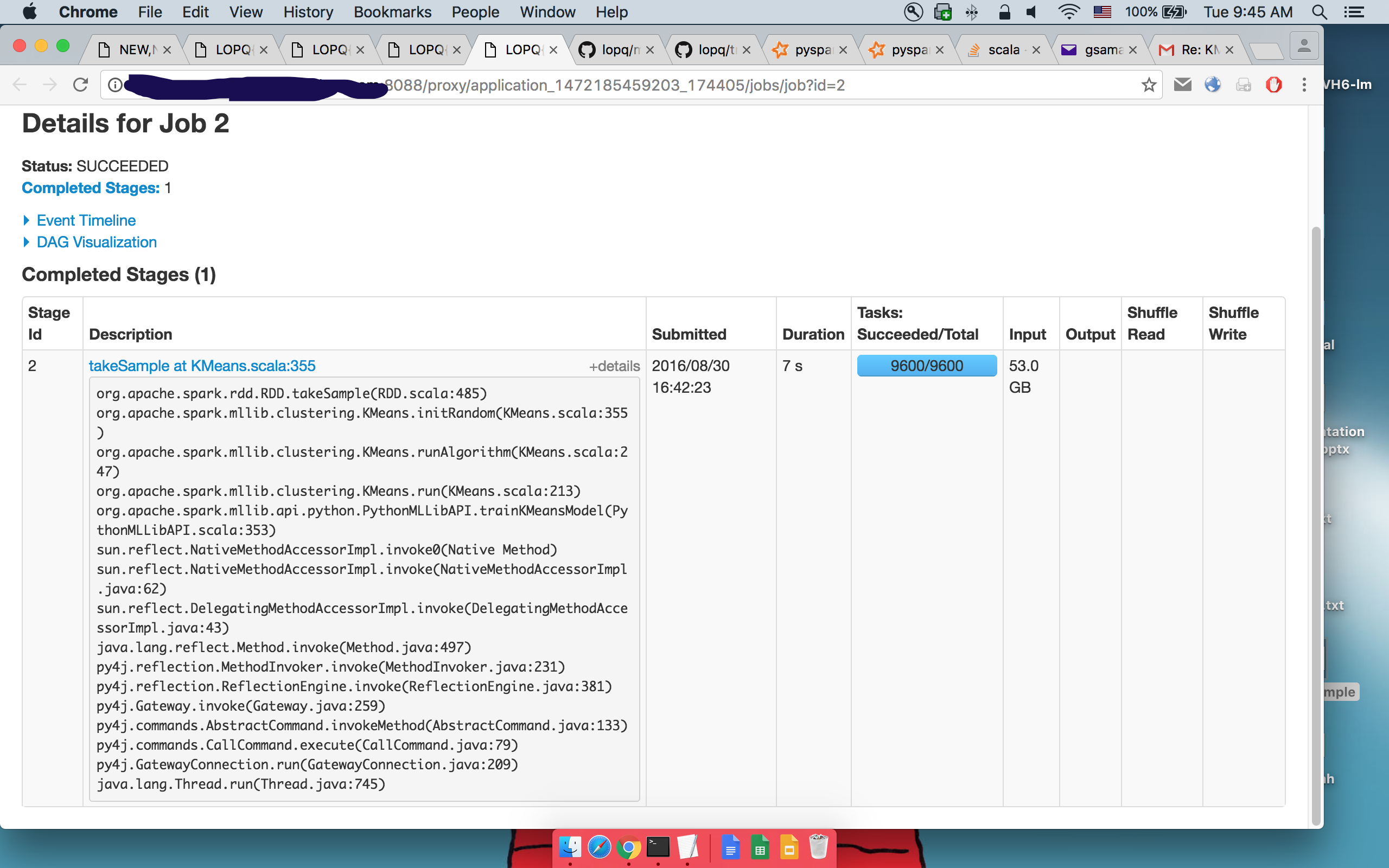
onde se pode ver que o mesmo código é executado.