Spark :: KMeans дважды вызывает takeSample ()?
У меня много данных, и я экспериментировал с разделами кардинальности [20k, 200k +].
Я называю это так:
from pyspark.mllib.clustering import KMeans, KMeansModel
C0 = KMeans.train(first, 8192, initializationMode='random', maxIterations=10, seed=None)
C0 = KMeans.train(second, 8192, initializationMode='random', maxIterations=10, seed=None)
и я вижу чтоinitRandom () звонкиtakeSample() один раз.
ТогдаtakeSample () реализация, кажется, не вызывает сама себя или что-то в этом роде, поэтому я ожидаюKMeans() звонитьtakeSample() один раз. Так почему монитор показывает дваtakeSample()с заKMeans()?
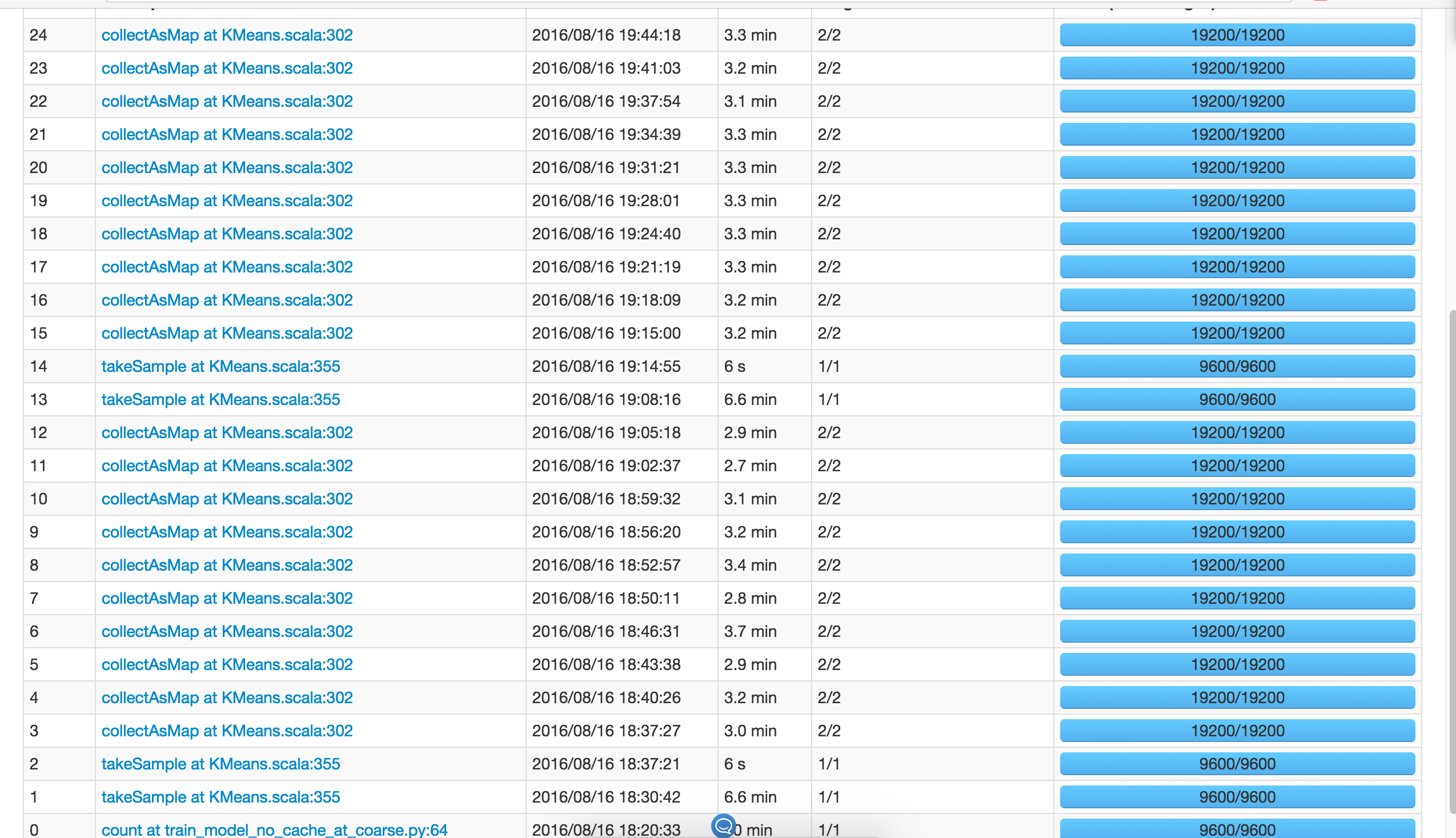
Примечание: я выполняю большеKMeans() и все они вызывают дваtakeSample()с, независимо от того, данные.cache()или нет.
Более того, количество разделов не влияет на количествоtakeSample() называется, это константа 2.
Я использую Spark 1.6.2 (и я не могу обновить), и мое приложение на Python, если это имеет значение!
Я внес это в список рассылки разработчиков Spark, поэтому я обновляю:
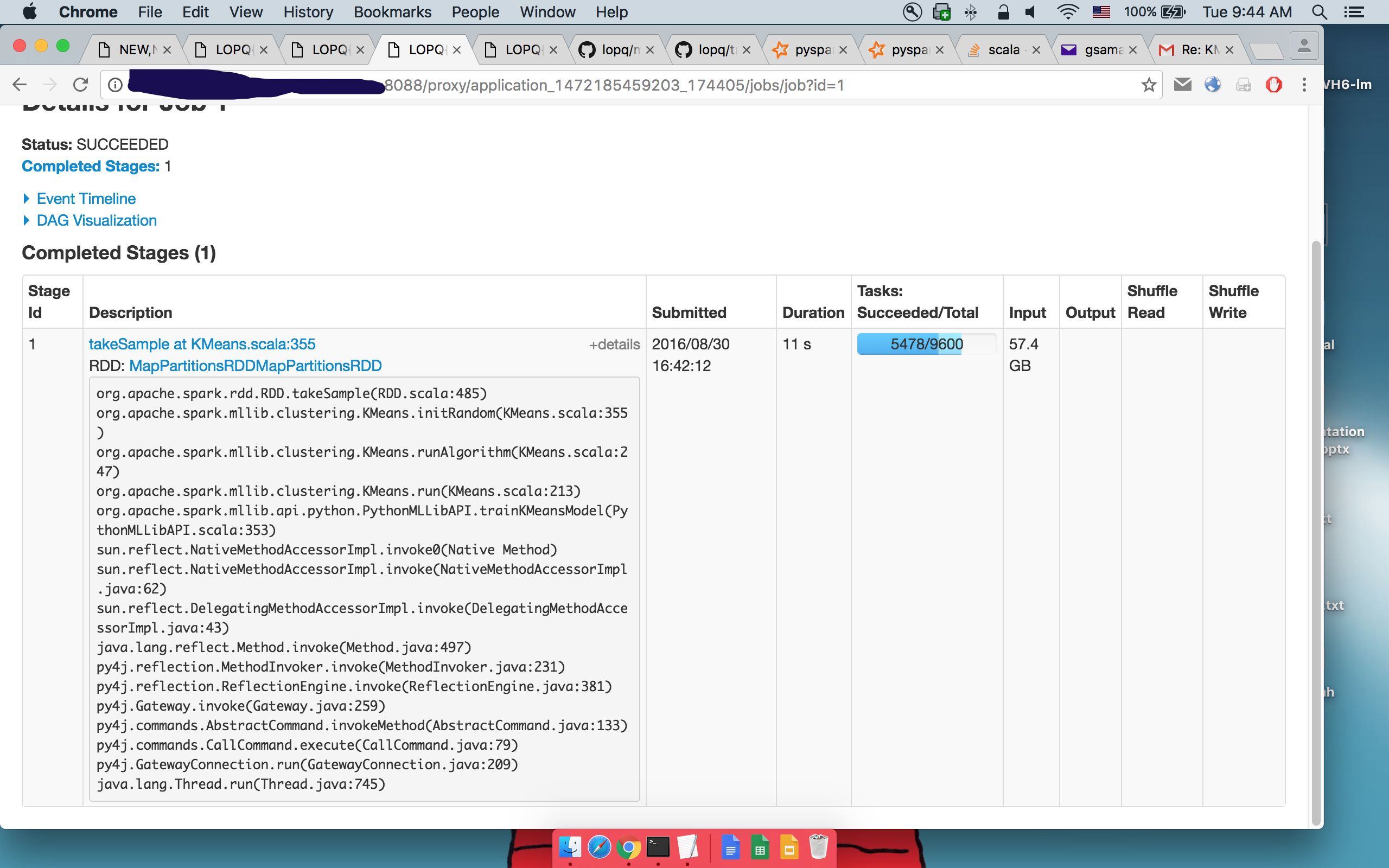
Подробности 1-гоtakeSample():
Подробности 2-гоtakeSample():
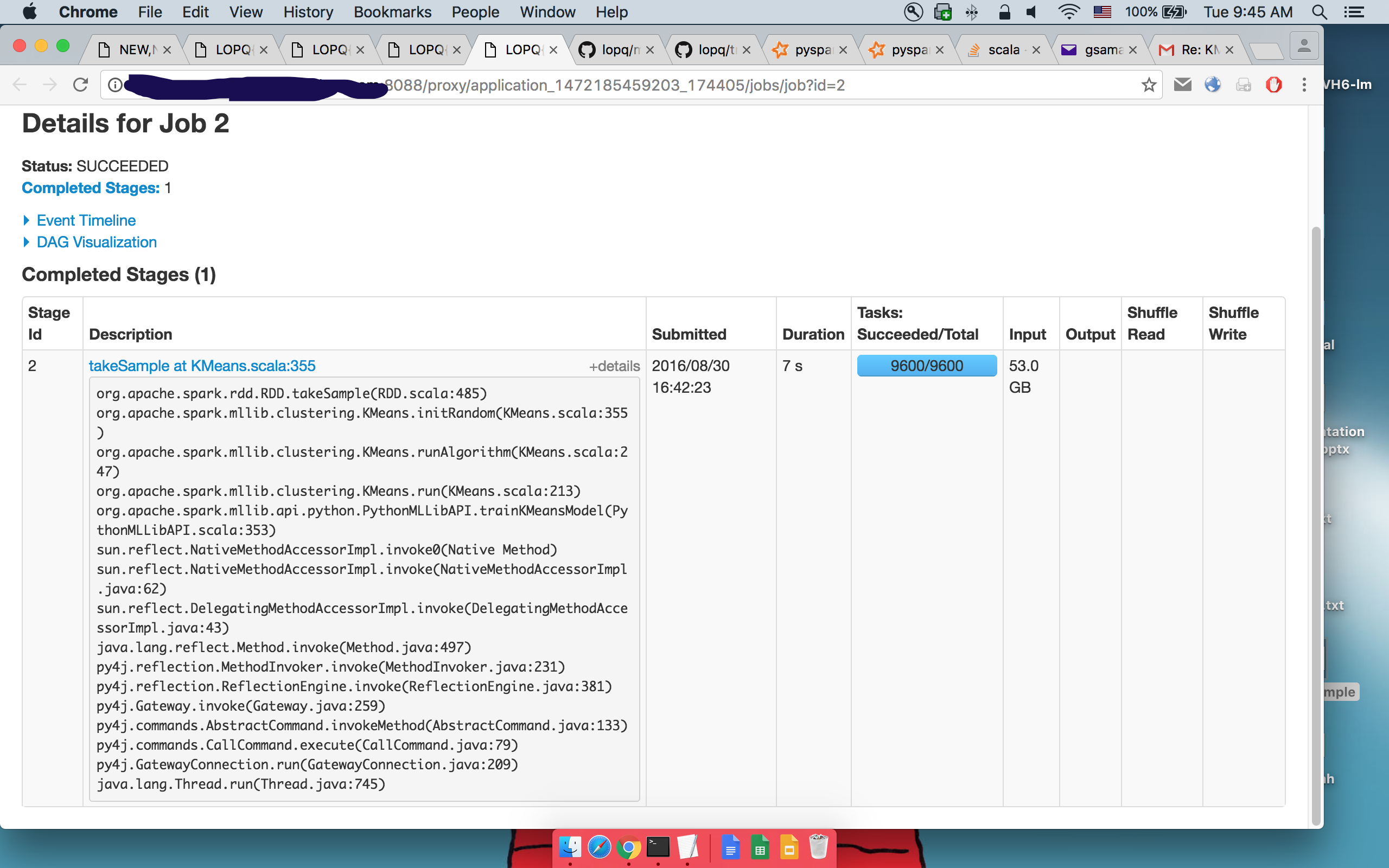
где можно увидеть, что тот же код выполняется.