Otimizando o acesso linear a matrizes com pré-busca e cache em C
divulgação: Eu tentei uma pergunta semelhante no programmers.stack, mas esse lugar não está nem perto da pilha de atividades.
Introdução
Costumo trabalhar com muitas imagens grandes. Eles também vêm em seqüências de mais de um e precisam ser processados e reproduzidos repetidamente. Às vezes eu uso GPU, às vezes CPU, às vezes ambos. A maioria dos padrões de acesso é de natureza linear (para frente e para trás), o que me fez pensar em coisas mais básicas sobre matrizes e como abordar a escrita de código otimizado para a largura de banda de memória máxima possível em um determinado hardware (permitindo que o cálculo não esteja bloqueando a leitura / gravação) .
Especificações de teste
Eu fiz isso em um MacbookAir4,2 2011 (I5-2557M) com 4 GB de RAM e SSD. Nada mais estava sendo executado durante os testes, exceto o iterm2.gcc 5.2.0 (homebrew) com sinalizadores:-pedantic -std=c99 -Wall -Werror -Wextra -Wno-unused -O0 com sinalizadores adicionais de inclusão e de biblioteca, bem como sinalizadores de estrutura para usar o glfw timer que eu costumo usar. Eu poderia ter feito isso sem, não importa. Tudo de 64 bits, é claro.Eu tentei testes com opcional-fprefetch-loop-arrays flag, mas não pareceu influenciar os resultadosTeste
Alocando duas matrizes den bytes na pilha - onden é8, 16, 32, 64, 128, 256, 512 and 1024 MBInicializararray para0xffbyte de cada vezTeste 1 - cópia linearcópia linear:
for(uint64_t i = 0; i < ARRAY_NUM; ++i) {
array_copy[i] = array[i];
}
malloc em c99 comuint64_t me daria bloco de memória alinhada. Também vejo tamanhos dos meus caches L1 a L3, superiores a esses320 bytes, então o que estou batendo? Pistas podem ser mais tarde nos gráficos. Eu realmente gostaria de entender isso.cópia do passo:
for(uint64_t i = 0; i < ARRAY_NUM; i=i+40) {
array_copy[i] = array[i];
array_copy[i+1] = array[i+1];
array_copy[i+2] = array[i+2];
array_copy[i+3] = array[i+3];
array_copy[i+4] = array[i+4];
array_copy[i+5] = array[i+5];
array_copy[i+6] = array[i+6];
array_copy[i+7] = array[i+7];
array_copy[i+8] = array[i+8];
array_copy[i+9] = array[i+9];
array_copy[i+10] = array[i+10];
array_copy[i+11] = array[i+11];
array_copy[i+12] = array[i+12];
array_copy[i+13] = array[i+13];
array_copy[i+14] = array[i+14];
array_copy[i+15] = array[i+15];
array_copy[i+16] = array[i+16];
array_copy[i+17] = array[i+17];
array_copy[i+18] = array[i+18];
array_copy[i+19] = array[i+19];
array_copy[i+20] = array[i+20];
array_copy[i+21] = array[i+21];
array_copy[i+22] = array[i+22];
array_copy[i+23] = array[i+23];
array_copy[i+24] = array[i+24];
array_copy[i+25] = array[i+25];
array_copy[i+26] = array[i+26];
array_copy[i+27] = array[i+27];
array_copy[i+28] = array[i+28];
array_copy[i+29] = array[i+29];
array_copy[i+30] = array[i+30];
array_copy[i+31] = array[i+31];
array_copy[i+32] = array[i+32];
array_copy[i+33] = array[i+33];
array_copy[i+34] = array[i+34];
array_copy[i+35] = array[i+35];
array_copy[i+36] = array[i+36];
array_copy[i+37] = array[i+37];
array_copy[i+38] = array[i+38];
array_copy[i+39] = array[i+39];
}
passo lido:
const int imax = 1000;
for(int j = 0; j < imax; ++j) {
uint64_t tmp = 0;
performance = 0;
time_start = glfwGetTime();
for(uint64_t i = 0; i < ARRAY_NUM; i=i+40) {
tmp = array[i];
tmp = array[i+1];
tmp = array[i+2];
tmp = array[i+3];
tmp = array[i+4];
tmp = array[i+5];
tmp = array[i+6];
tmp = array[i+7];
tmp = array[i+8];
tmp = array[i+9];
tmp = array[i+10];
tmp = array[i+11];
tmp = array[i+12];
tmp = array[i+13];
tmp = array[i+14];
tmp = array[i+15];
tmp = array[i+16];
tmp = array[i+17];
tmp = array[i+18];
tmp = array[i+19];
tmp = array[i+20];
tmp = array[i+21];
tmp = array[i+22];
tmp = array[i+23];
tmp = array[i+24];
tmp = array[i+25];
tmp = array[i+26];
tmp = array[i+27];
tmp = array[i+28];
tmp = array[i+29];
tmp = array[i+30];
tmp = array[i+31];
tmp = array[i+32];
tmp = array[i+33];
tmp = array[i+34];
tmp = array[i+35];
tmp = array[i+36];
tmp = array[i+37];
tmp = array[i+38];
tmp = array[i+39];
}
-fprefetch-loop-arrays não produziu resultados aqui. Eu pensei que era para esses casos.leitura linear:
for(uint64_t i = 0; i < ARRAY_NUM; ++i) {
tmp = array[i];
}
memcpy como um contraste.memcpy:
memcpy(array_copy, array, ARRAY_NUM*sizeof(uint64_t));
Resultados
Saída de amostra:saída de amostra:
Init done in 0.767 s - size of array: 1024 MBs (x2)
Performance: 1304.325 MB/s
Copying (linear) done in 0.898 s
Performance: 1113.529 MB/s
Copying (stride 40) done in 0.257 s
Performance: 3890.608 MB/s
[1000/1000] Performance stride 40: 7474.322 MB/s
Average: 7523.427 MB/s
Performance MIN: 3231 MB/s | Performance MAX: 7818 MB/s
[1000/1000] Performance dumb: 2504.713 MB/s
Average: 2481.502 MB/s
Performance MIN: 1572 MB/s | Performance MAX: 2644 MB/s
Copying (memcpy) done in 1.726 s
Performance: 579.485 MB/s
--
Init done in 0.415 s - size of array: 512 MBs (x2)
Performance: 1233.136 MB/s
Copying (linear) done in 0.442 s
Performance: 1157.147 MB/s
Copying (stride 40) done in 0.116 s
Performance: 4399.606 MB/s
[1000/1000] Performance stride 40: 6527.004 MB/s
Average: 7166.458 MB/s
Performance MIN: 4359 MB/s | Performance MAX: 7787 MB/s
[1000/1000] Performance dumb: 2383.292 MB/s
Average: 2409.005 MB/s
Performance MIN: 1673 MB/s | Performance MAX: 2641 MB/s
Copying (memcpy) done in 0.102 s
Performance: 5026.476 MB/s
--
Init done in 0.228 s - size of array: 256 MBs (x2)
Performance: 1124.618 MB/s
Copying (linear) done in 0.242 s
Performance: 1057.916 MB/s
Copying (stride 40) done in 0.070 s
Performance: 3650.996 MB/s
[1000/1000] Performance stride 40: 7129.206 MB/s
Average: 7370.537 MB/s
Performance MIN: 4805 MB/s | Performance MAX: 7848 MB/s
[1000/1000] Performance dumb: 2456.129 MB/s
Average: 2435.556 MB/s
Performance MIN: 1496 MB/s | Performance MAX: 2637 MB/s
Copying (memcpy) done in 0.050 s
Performance: 5095.845 MB/s
--
Init done in 0.100 s - size of array: 128 MBs (x2)
Performance: 1277.200 MB/s
Copying (linear) done in 0.112 s
Performance: 1147.030 MB/s
Copying (stride 40) done in 0.029 s
Performance: 4424.513 MB/s
[1000/1000] Performance stride 40: 6497.635 MB/s
Average: 6714.540 MB/s
Performance MIN: 4206 MB/s | Performance MAX: 7843 MB/s
[1000/1000] Performance dumb: 2275.336 MB/s
Average: 2335.544 MB/s
Performance MIN: 1572 MB/s | Performance MAX: 2626 MB/s
Copying (memcpy) done in 0.025 s
Performance: 5086.502 MB/s
--
Init done in 0.051 s - size of array: 64 MBs (x2)
Performance: 1255.969 MB/s
Copying (linear) done in 0.058 s
Performance: 1104.282 MB/s
Copying (stride 40) done in 0.015 s
Performance: 4305.765 MB/s
[1000/1000] Performance stride 40: 7750.063 MB/s
Average: 7412.167 MB/s
Performance MIN: 3892 MB/s | Performance MAX: 7826 MB/s
[1000/1000] Performance dumb: 2610.136 MB/s
Average: 2577.313 MB/s
Performance MIN: 2126 MB/s | Performance MAX: 2652 MB/s
Copying (memcpy) done in 0.013 s
Performance: 4871.823 MB/s
--
Init done in 0.024 s - size of array: 32 MBs (x2)
Performance: 1306.738 MB/s
Copying (linear) done in 0.028 s
Performance: 1148.582 MB/s
Copying (stride 40) done in 0.008 s
Performance: 4265.907 MB/s
[1000/1000] Performance stride 40: 6181.040 MB/s
Average: 7124.592 MB/s
Performance MIN: 3480 MB/s | Performance MAX: 7777 MB/s
[1000/1000] Performance dumb: 2508.669 MB/s
Average: 2556.529 MB/s
Performance MIN: 1966 MB/s | Performance MAX: 2646 MB/s
Copying (memcpy) done in 0.007 s
Performance: 4617.860 MB/s
--
Init done in 0.013 s - size of array: 16 MBs (x2)
Performance: 1243.011 MB/s
Copying (linear) done in 0.014 s
Performance: 1139.362 MB/s
Copying (stride 40) done in 0.004 s
Performance: 4181.548 MB/s
[1000/1000] Performance stride 40: 6317.129 MB/s
Average: 7358.539 MB/s
Performance MIN: 5250 MB/s | Performance MAX: 7816 MB/s
[1000/1000] Performance dumb: 2529.707 MB/s
Average: 2525.783 MB/s
Performance MIN: 1823 MB/s | Performance MAX: 2634 MB/s
Copying (memcpy) done in 0.003 s
Performance: 5167.561 MB/s
--
Init done in 0.007 s - size of array: 8 MBs (x2)
Performance: 1186.019 MB/s
Copying (linear) done in 0.007 s
Performance: 1147.018 MB/s
Copying (stride 40) done in 0.002 s
Performance: 4157.658 MB/s
[1000/1000] Performance stride 40: 6958.839 MB/s
Average: 7097.742 MB/s
Performance MIN: 4278 MB/s | Performance MAX: 7499 MB/s
[1000/1000] Performance dumb: 2585.366 MB/s
Average: 2537.896 MB/s
Performance MIN: 2284 MB/s | Performance MAX: 2610 MB/s
Copying (memcpy) done in 0.002 s
Performance: 5059.164 MB/s
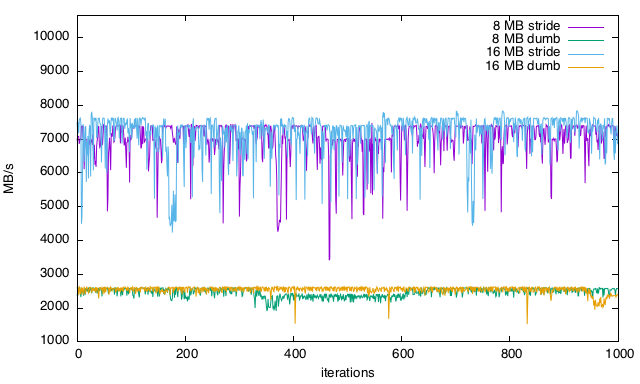
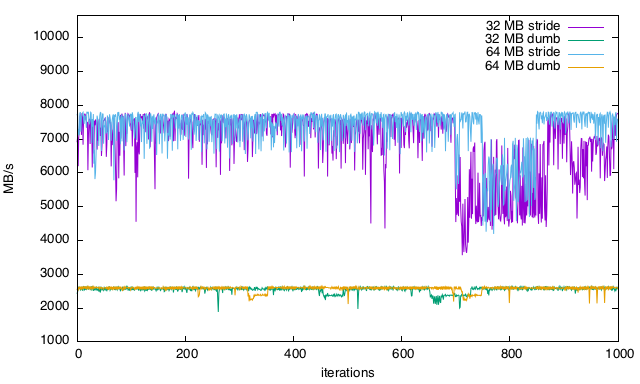
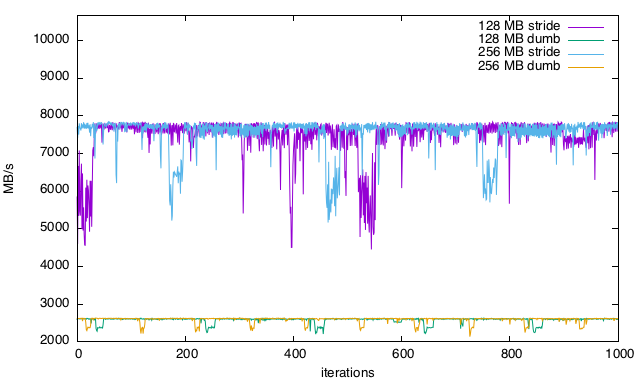
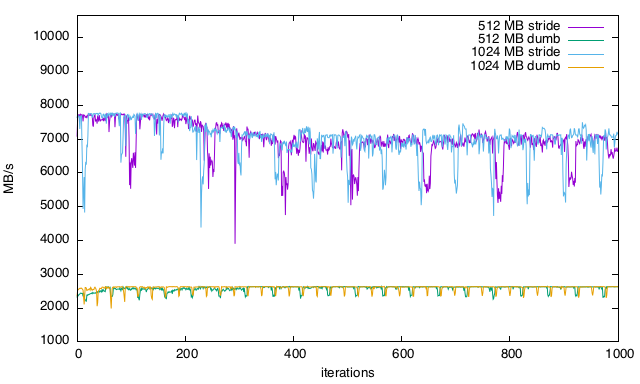
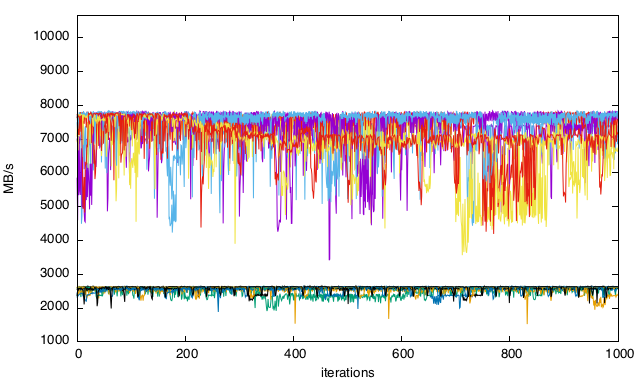
10,664 MB/s então por que não estou acertando? Por que a velocidade de leitura não é mais consistente e como eu otimizaria isso (falhas de cache?)? É mais aparente nos gráficos, especialmente na leitura linear com quedas regulares no desempenho.Gráficos
8-16 MB
32-64 MB
128-256 MB
512-1024 MB
Todos juntos
Aqui está a fonte completa para qualquer pessoa interessada:
/*
gcc -pedantic -std=c99 -Wall -Werror -Wextra -Wno-unused -O0 -I "...path to glfw3 includes ..." -L "...path to glfw3 lib ..." arr_test_copy_gnuplot.c -o arr_test_copy_gnuplot -lglfw3 -framework OpenGL -framework Cocoa -framework IOKit -framework CoreVideo
optional: -fprefetch-loop-arrays
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h> /* memcpy */
#include <inttypes.h>
#include <GLFW/glfw3.h>
#define ARRAY_NUM 1000000 * 128 /* GIG */
int main(int argc, char *argv[]) {
if(!glfwInit()) {
exit(EXIT_FAILURE);
}
int cx = 0;
char filename_stride[50];
char filename_dumb[50];
cx = snprintf(filename_stride, 50, "%lu_stride.dat",
((ARRAY_NUM*sizeof(uint64_t))/1000000));
if(cx < 0 || cx >50) { exit(EXIT_FAILURE); }
FILE *file_stride = fopen(filename_stride, "w");
cx = snprintf(filename_dumb, 50, "%lu_dumb.dat",
((ARRAY_NUM*sizeof(uint64_t))/1000000));
if(cx < 0 || cx >50) { exit(EXIT_FAILURE); }
FILE *file_dumb = fopen(filename_dumb, "w");
if(file_stride == NULL || file_dumb == NULL) {
perror("Error opening file.");
exit(EXIT_FAILURE);
}
uint64_t *array = malloc(sizeof(uint64_t) * ARRAY_NUM);
uint64_t *array_copy = malloc(sizeof(uint64_t) * ARRAY_NUM);
double performance = 0.0;
double time_start = 0.0;
double time_end = 0.0;
double performance_min = 0.0;
double performance_max = 0.0;
/* Init array */
time_start = glfwGetTime();
for(uint64_t i = 0; i < ARRAY_NUM; ++i) {
array[i] = 0xff;
}
time_end = glfwGetTime();
performance = ((ARRAY_NUM * sizeof(uint64_t))/1000000) / (time_end - time_start);
printf("Init done in %.3f s - size of array: %lu MBs (x2)\n", (time_end - time_start), (ARRAY_NUM*sizeof(uint64_t)/1000000));
printf("Performance: %.3f MB/s\n\n", performance);
/* Linear copy */
performance = 0;
time_start = glfwGetTime();
for(uint64_t i = 0; i < ARRAY_NUM; ++i) {
array_copy[i] = array[i];
}
time_end = glfwGetTime();
performance = ((ARRAY_NUM * sizeof(uint64_t))/1000000) / (time_end - time_start);
printf("Copying (linear) done in %.3f s\n", (time_end - time_start));
printf("Performance: %.3f MB/s\n\n", performance);
/* Copying with wide stride */
performance = 0;
time_start = glfwGetTime();
for(uint64_t i = 0; i < ARRAY_NUM; i=i+40) {
array_copy[i] = array[i];
array_copy[i+1] = array[i+1];
array_copy[i+2] = array[i+2];
array_copy[i+3] = array[i+3];
array_copy[i+4] = array[i+4];
array_copy[i+5] = array[i+5];
array_copy[i+6] = array[i+6];
array_copy[i+7] = array[i+7];
array_copy[i+8] = array[i+8];
array_copy[i+9] = array[i+9];
array_copy[i+10] = array[i+10];
array_copy[i+11] = array[i+11];
array_copy[i+12] = array[i+12];
array_copy[i+13] = array[i+13];
array_copy[i+14] = array[i+14];
array_copy[i+15] = array[i+15];
array_copy[i+16] = array[i+16];
array_copy[i+17] = array[i+17];
array_copy[i+18] = array[i+18];
array_copy[i+19] = array[i+19];
array_copy[i+20] = array[i+20];
array_copy[i+21] = array[i+21];
array_copy[i+22] = array[i+22];
array_copy[i+23] = array[i+23];
array_copy[i+24] = array[i+24];
array_copy[i+25] = array[i+25];
array_copy[i+26] = array[i+26];
array_copy[i+27] = array[i+27];
array_copy[i+28] = array[i+28];
array_copy[i+29] = array[i+29];
array_copy[i+30] = array[i+30];
array_copy[i+31] = array[i+31];
array_copy[i+32] = array[i+32];
array_copy[i+33] = array[i+33];
array_copy[i+34] = array[i+34];
array_copy[i+35] = array[i+35];
array_copy[i+36] = array[i+36];
array_copy[i+37] = array[i+37];
array_copy[i+38] = array[i+38];
array_copy[i+39] = array[i+39];
}
time_end = glfwGetTime();
performance = ((ARRAY_NUM * sizeof(uint64_t))/1000000) / (time_end - time_start);
printf("Copying (stride 40) done in %.3f s\n", (time_end - time_start));
printf("Performance: %.3f MB/s\n\n", performance);
/* Reading with wide stride */
const int imax = 1000;
double performance_average = 0.0;
for(int j = 0; j < imax; ++j) {
uint64_t tmp = 0;
performance = 0;
time_start = glfwGetTime();
for(uint64_t i = 0; i < ARRAY_NUM; i=i+40) {
tmp = array[i];
tmp = array[i+1];
tmp = array[i+2];
tmp = array[i+3];
tmp = array[i+4];
tmp = array[i+5];
tmp = array[i+6];
tmp = array[i+7];
tmp = array[i+8];
tmp = array[i+9];
tmp = array[i+10];
tmp = array[i+11];
tmp = array[i+12];
tmp = array[i+13];
tmp = array[i+14];
tmp = array[i+15];
tmp = array[i+16];
tmp = array[i+17];
tmp = array[i+18];
tmp = array[i+19];
tmp = array[i+20];
tmp = array[i+21];
tmp = array[i+22];
tmp = array[i+23];
tmp = array[i+24];
tmp = array[i+25];
tmp = array[i+26];
tmp = array[i+27];
tmp = array[i+28];
tmp = array[i+29];
tmp = array[i+30];
tmp = array[i+31];
tmp = array[i+32];
tmp = array[i+33];
tmp = array[i+34];
tmp = array[i+35];
tmp = array[i+36];
tmp = array[i+37];
tmp = array[i+38];
tmp = array[i+39];
}
time_end = glfwGetTime();
performance = ((ARRAY_NUM * sizeof(uint64_t))/1000000) / (time_end - time_start);
performance_average += performance;
if(performance > performance_max) { performance_max = performance; }
if(j == 0) { performance_min = performance; }
if(performance < performance_min) { performance_min = performance; }
printf("[%d/%d] Performance stride 40: %.3f MB/s\r", j+1, imax, performance);
fprintf(file_stride, "%d\t%f\n", j, performance);
fflush(file_stride);
fflush(stdout);
}
performance_average = performance_average / imax;
printf("\nAverage: %.3f MB/s\n", performance_average);
printf("Performance MIN: %3.f MB/s | Performance MAX: %3.f MB/s\n\n",
performance_min, performance_max);
/* Linear reading */
performance_average = 0.0;
performance_min = 0.0;
performance_max = 0.0;
for(int j = 0; j < imax; ++j) {
uint64_t tmp = 0;
performance = 0;
time_start = glfwGetTime();
for(uint64_t i = 0; i < ARRAY_NUM; ++i) {
tmp = array[i];
}
time_end = glfwGetTime();
performance = ((ARRAY_NUM * sizeof(uint64_t))/1000000) / (time_end - time_start);
performance_average += performance;
if(performance > performance_max) { performance_max = performance; }
if(j == 0) { performance_min = performance; }
if(performance < performance_min) { performance_min = performance; }
printf("[%d/%d] Performance dumb: %.3f MB/s\r", j+1, imax, performance);
fprintf(file_dumb, "%d\t%f\n", j, performance);
fflush(file_dumb);
fflush(stdout);
}
performance_average = performance_average / imax;
printf("\nAverage: %.3f MB/s\n", performance_average);
printf("Performance MIN: %3.f MB/s | Performance MAX: %3.f MB/s\n\n",
performance_min, performance_max);
/* Memcpy */
performance = 0;
time_start = glfwGetTime();
memcpy(array_copy, array, ARRAY_NUM*sizeof(uint64_t));
time_end = glfwGetTime();
performance = ((ARRAY_NUM * sizeof(uint64_t))/1000000) / (time_end - time_start);
printf("Copying (memcpy) done in %.3f s\n", (time_end - time_start));
printf("Performance: %.3f MB/s\n", performance);
/* Cleanup and exit */
free(array);
free(array_copy);
glfwTerminate();
fclose(file_dumb);
fclose(file_stride);
exit(EXIT_SUCCESS);
}
Sumário
Como devo escrever código para ter velocidade máxima e (quase) constante ao trabalhar com matrizes onde o acesso linear é o padrão mais comum?O que posso aprender sobre cache e pré-busca neste exemplo?Esses gráficos estão me dizendo algo que eu deveria saber que não notei?De que outra forma posso desenrolar loops? eu tentei-funroll-loops sem resultados, por isso recorri à gravação manual de desenrolamentos loop-in-loop.Obrigado pela leitura longa.
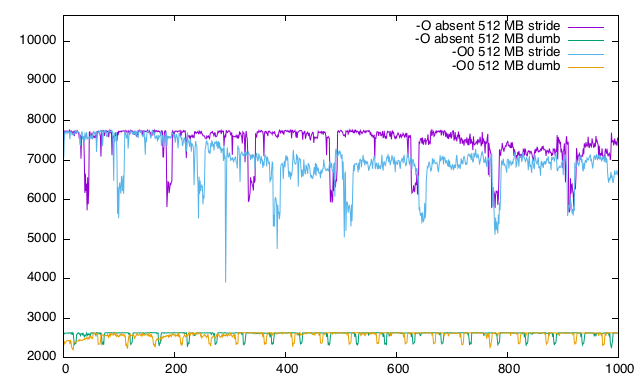
EDITAR:
Parece-O0 dá um desempenho diferente de quando-O bandeira está ausente! O que da? A ausência de sinalizador produz um melhor desempenho, como pode ser visto no gráfico.
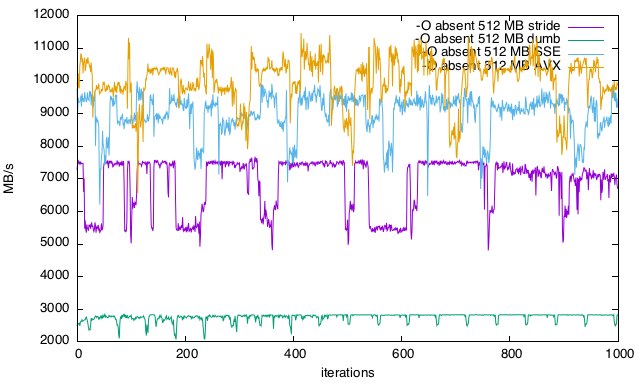
EDIT2:
Finalmente atingi o teto com o AVX.
=== READING WITH AVX ===
[1000/1000] Performance AVX: 9868.912 MB/s
Average: 10029.085 MB/s
Performance MIN: 6554 MB/s | Performance MAX: 11464 MB/s
Média sendo realmente muito próxima de 10664. Eu tive que mudar o compilador para clang porque o gcc estava me dando dificuldades para usar o avx (-mavx). É também por isso que o gráfico tem quedas mais pronunciadas. Eu ainda gostaria de saber como / o que é / tenho desempenho constante. Presumo que isso se deva a linhas de cache / cache. Isso também explicaria o desempenho acima da velocidade DDR3 aqui e ali (o MAX era 11464 MB / s).
Desculpe meu gnuplot-fu e suas chaves. Azul é SSE2 (_mm_load_si128 ) e laranja é AVX (_mm256_load_si256 ) O roxo é feito como antes e o verde é uma leitura muda, uma de cada vez.
Portanto, as duas questões finais são:
O que está causando quedas e como ter um desempenho mais constanteÉ possível atingir o teto sem intrínsecas?essência com a versão mais recente:https://gist.github.com/Keyframe/1ed9062ec52fc4a0d14b e gráficos dessa versão:http://imgur.com/a/cPeor