R ggplot2 boxplots - ggpubr stat_compare_means no funciona correctamente
Estoy tratando de agregar niveles de importancia a midiagramas de caja en forma de asteriscos usandoggplot2 y elggpubr paquete, pero tengo muchas comparaciones y solo quiero mostrar las significativas.
Trato de usar la opcionhide.ns = TRUE enstat_compare_means, pero claramenteNo funciona, podría ser un error en elggpubr paquete.
Además, ves que dejo fuera el grupo "PGMC4" del parwilcox.test comparaciones ¿Cómo puedo dejar este grupo también para elkruskal.test?
La última pregunta que tengo es cómo funciona el nivel de significación. Como en * es significativo por debajo de 0.05, ** por debajo de 0.025, *** por debajo de 0.01? ¿Cuál es la convención que utiliza ggpubr? ¿Muestra valores p o valores p ajustados? Si es esto último, ¿cuál es el método de ajuste? BH?
Por favor revise mi MWE a continuación yeste enlace yeste otro para referencia
##############################
##MWE
set.seed(5)
#test df
mydf <- data.frame(ID=paste(sample(LETTERS, 163, replace=TRUE), sample(1:1000, 163, replace=FALSE), sep=''),
Group=c(rep('C',10),rep('FH',10),rep('I',19),rep('IF',42),rep('NA',14),rep('NF',42),rep('NI',15),rep('NS',10),rep('PGMC4',1)),
Value=rnorm(n=163))
#I don't want to compare PGMC4 cause I have only onw sample
groups <- as.character(unique(mydf$Group[which(mydf$Group!="PGMC4")]))
#function to make combinations of groups without repeating pairs, and avoiding self-combinations
expand.grid.unique <- function(x, y, include.equals=FALSE){
x <- unique(x)
y <- unique(y)
g <- function(i){
z <- setdiff(y, x[seq_len(i-include.equals)])
if(length(z)) cbind(x[i], z, deparse.level=0)
}
do.call(rbind, lapply(seq_along(x), g))
}
#all pairs I want to compare
combs <- as.data.frame(expand.grid.unique(groups, groups), stringsAsFactors=FALSE)
head(combs)
my.comps <- as.data.frame(t(combs), stringsAsFactors=FALSE)
colnames(my.comps) <- NULL
rownames(my.comps) <- NULL
#pairs I want to compare in list format for stat_compare_means
my.comps <- as.list(my.comps)
head(my.comps)
pdf(file="test.pdf", height=20, width=25)
print(#or ggsave()
ggplot(mydf, aes(x=Group, y=Value, fill=Group)) + geom_boxplot() +
stat_summary(fun.y=mean, geom="point", shape=5, size=4) +
scale_fill_manual(values=myPal) +
ggtitle("TEST TITLE") +
theme(plot.title = element_text(size=30),
axis.text=element_text(size=12),
axis.text.x = element_text(angle=45, hjust=1),
axis.ticks = element_blank(),
axis.title=element_text(size=20,face="bold"),
legend.text=element_text(size=16)) +
stat_compare_means(comparisons=my.comps, method="wilcox.test", label="p.signif", size=14) + #WHY DOES hide.ns=TRUE NOT WORK??? WHY DOES size=14 NOT WORK???
stat_compare_means(method="kruskal.test", size=14) #GLOBAL COMPARISON ACROSS GROUPS (HOW TO LEAVE PGMC4 OUT OF THIS??)
)
dev.off()
##############################
El MWE producirá los siguientes diagramas de caja:
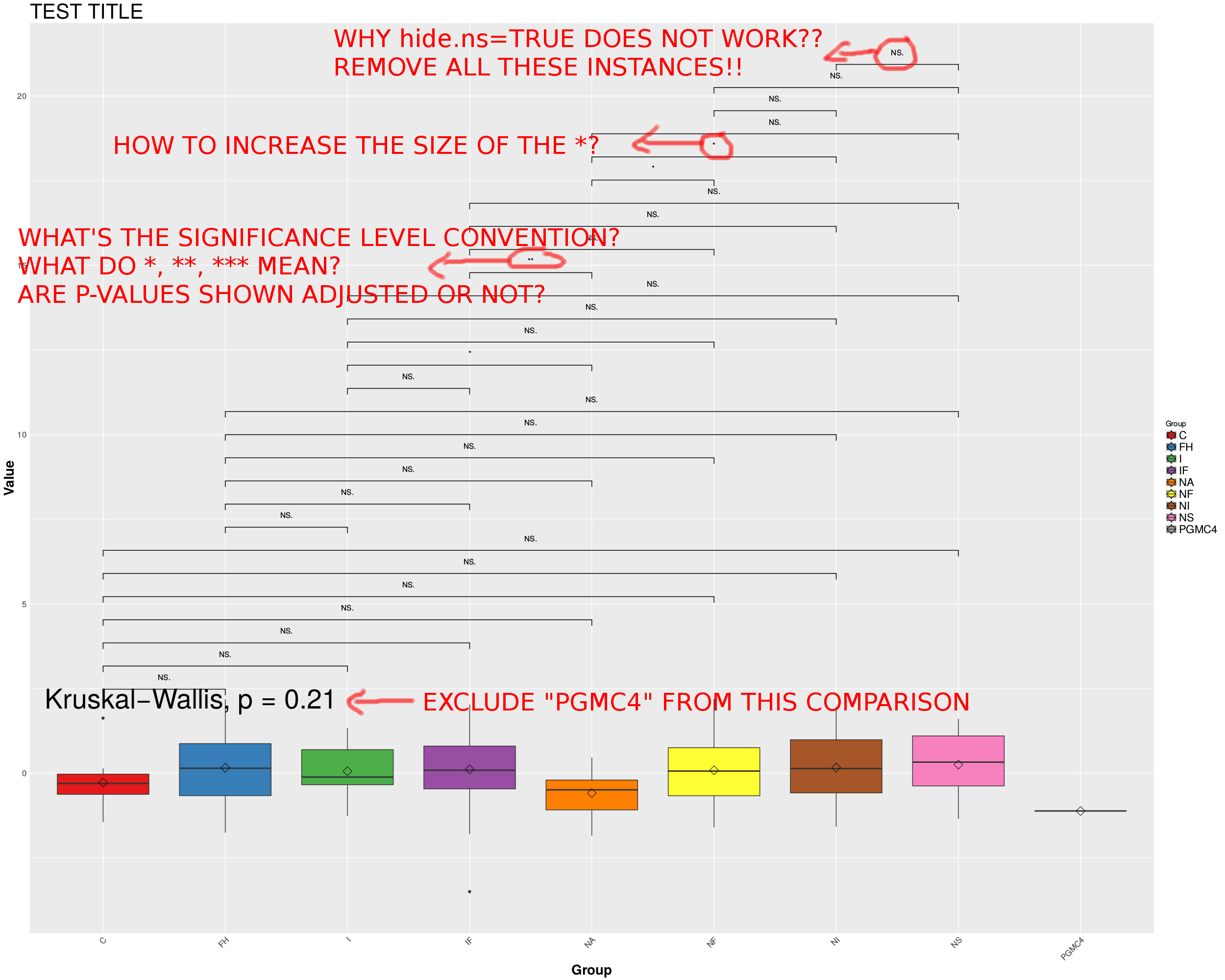
Las preguntas serían:
1- ¿Cómo hacer que hide.ns = TRUE funcione?
2- ¿Cómo aumentar el tamaño de *?
3- ¿Cómo excluir un grupo de la comparación kruskal.test?
4- ¿Cuál es la convención * utilizada por ggpubr, y los valores p mostrados están ajustados o no?
¡¡Muchas gracias!!
EDITAR
Además, al hacer
stat_compare_means(comparisons=my.comps, method="wilcox.test", p.adjust.method="BH")
No obtengo los mismos valores p que cuando hago
wilcox.test(Value ~ Group, data=mydf.sub)$p.value
donde mydf.sub es un subconjunto () de mydf para una comparación dada de 2 grupos.
¿Qué está haciendo ggpubr aquí? ¿Cómo calcula los valores p?
EDITAR 2
Por favor ayuda, la solución no tiene que estar con ggpubr (pero tiene que estar conggplot2), Solo necesito poder ocultar el NS y aumentar el tamaño de los asteriscos, así como un cálculo del valor p idéntico a wilcox.test () + p.adjust (método "BH").
¡Gracias!