R ggplot2 boxplots - ggpubr stat_compare_means não está funcionando corretamente
Estou tentando adicionar níveis de significância ao meuboxplots na forma de asteriscos usandoggplot2 e aggpubr pacote, mas tenho muitas comparações e só quero mostrar as significativas.
Eu tento usar a opçãohide.ns = TRUE nostat_compare_means, mas claramentenão funciona, pode ser um bug noggpubr pacote.
Além disso, você vê que eu deixo de fora o grupo "PGMC4" do parwilcox.test comparações; como posso deixar esse grupo de fora também para okruskal.test?
A última pergunta que tenho é como o nível de significância funciona? Como * é significativo abaixo de 0,05, ** abaixo de 0,025, *** abaixo de 0,01? qual é a convenção que o ggpubr usa? Está mostrando valores de p ou valores de p ajustados? Neste último caso, qual é o método de ajuste? BH?
Por favor, verifique meu MWE abaixo eesse link eesse outro para referência
##############################
##MWE
set.seed(5)
#test df
mydf <- data.frame(ID=paste(sample(LETTERS, 163, replace=TRUE), sample(1:1000, 163, replace=FALSE), sep=''),
Group=c(rep('C',10),rep('FH',10),rep('I',19),rep('IF',42),rep('NA',14),rep('NF',42),rep('NI',15),rep('NS',10),rep('PGMC4',1)),
Value=rnorm(n=163))
#I don't want to compare PGMC4 cause I have only onw sample
groups <- as.character(unique(mydf$Group[which(mydf$Group!="PGMC4")]))
#function to make combinations of groups without repeating pairs, and avoiding self-combinations
expand.grid.unique <- function(x, y, include.equals=FALSE){
x <- unique(x)
y <- unique(y)
g <- function(i){
z <- setdiff(y, x[seq_len(i-include.equals)])
if(length(z)) cbind(x[i], z, deparse.level=0)
}
do.call(rbind, lapply(seq_along(x), g))
}
#all pairs I want to compare
combs <- as.data.frame(expand.grid.unique(groups, groups), stringsAsFactors=FALSE)
head(combs)
my.comps <- as.data.frame(t(combs), stringsAsFactors=FALSE)
colnames(my.comps) <- NULL
rownames(my.comps) <- NULL
#pairs I want to compare in list format for stat_compare_means
my.comps <- as.list(my.comps)
head(my.comps)
pdf(file="test.pdf", height=20, width=25)
print(#or ggsave()
ggplot(mydf, aes(x=Group, y=Value, fill=Group)) + geom_boxplot() +
stat_summary(fun.y=mean, geom="point", shape=5, size=4) +
scale_fill_manual(values=myPal) +
ggtitle("TEST TITLE") +
theme(plot.title = element_text(size=30),
axis.text=element_text(size=12),
axis.text.x = element_text(angle=45, hjust=1),
axis.ticks = element_blank(),
axis.title=element_text(size=20,face="bold"),
legend.text=element_text(size=16)) +
stat_compare_means(comparisons=my.comps, method="wilcox.test", label="p.signif", size=14) + #WHY DOES hide.ns=TRUE NOT WORK??? WHY DOES size=14 NOT WORK???
stat_compare_means(method="kruskal.test", size=14) #GLOBAL COMPARISON ACROSS GROUPS (HOW TO LEAVE PGMC4 OUT OF THIS??)
)
dev.off()
##############################
O MWE produzirá os seguintes boxplots:
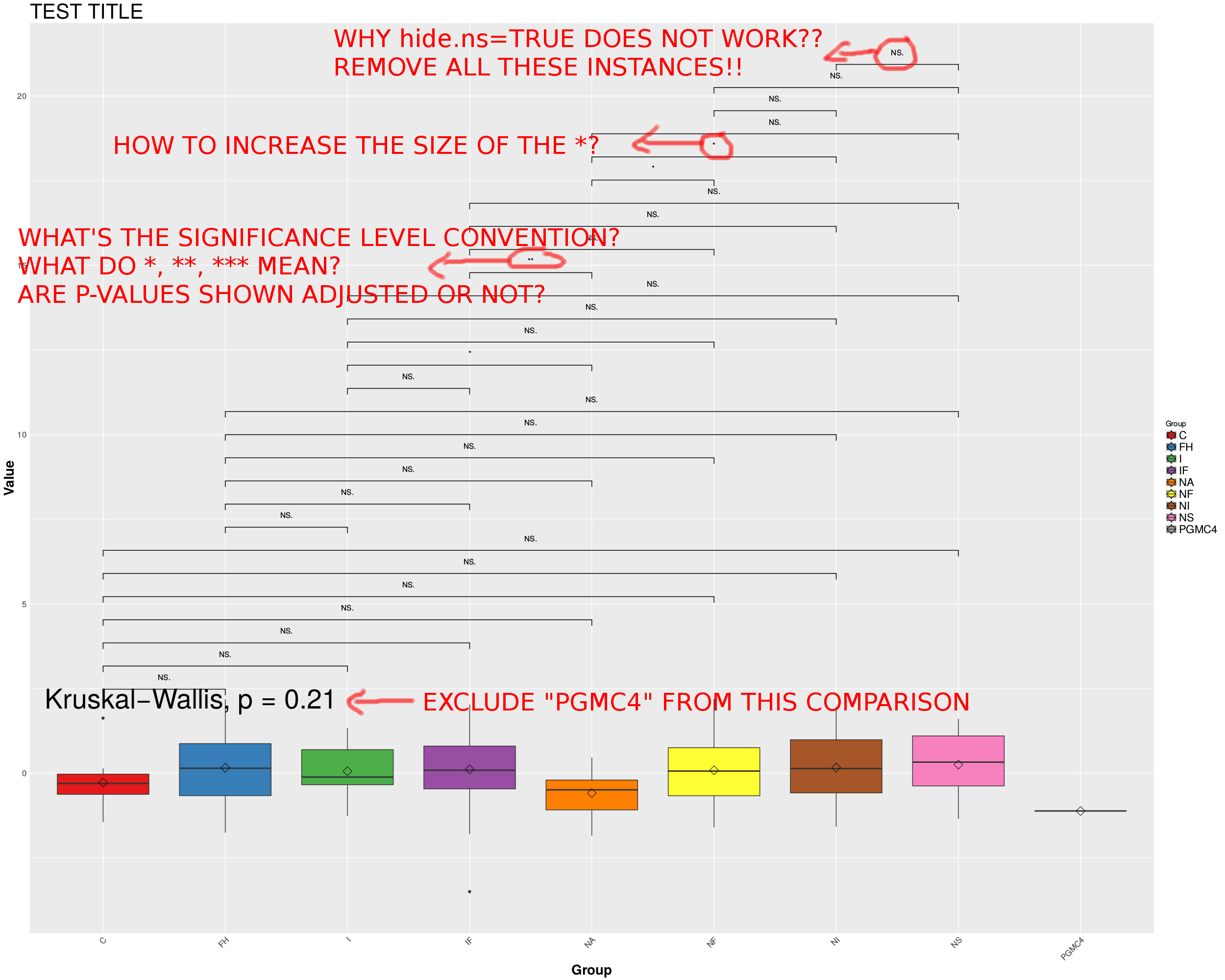
As perguntas seriam:
1- Como fazer hide.ns = TRUE funcionar?
2- Como aumentar o tamanho do *?
3- Como excluir um grupo da comparação kruskal.test?
4- Qual é a convenção * usada pelo ggpubr e os valores de p mostrados são ajustados ou não?
Muito Obrigado!!
EDITAR
Além disso, ao fazer
stat_compare_means(comparisons=my.comps, method="wilcox.test", p.adjust.method="BH")
Eu não obtenho os mesmos valores p de quando faço
wilcox.test(Value ~ Group, data=mydf.sub)$p.value
onde mydf.sub é um subconjunto () de mydf para uma determinada comparação de 2 grupos.
O que ggpubr está fazendo aqui? Como ele calcula os valores de p?
EDIT 2
Por favor, ajude, a solução não precisa estar com o ggpubr (mas deve estar comggplot2), Só preciso ocultar o NS e aumentar o tamanho dos asteriscos, além de um cálculo do valor de p idêntico ao wilcox.test () + p.adjust (método "BH").
Obrigado!