Trabajando con, preparando datos de bolsa de palabras para Regresión
Estoy tratando de crear un modelo de regresión que prediga la edad de un autor. Estoy usando (Nguyen et al, 2011) como mi base.
Usando un modelo de bolsa de palabras, cuento las ocurrencias de las palabras por documento (que son publicaciones de tableros) y creo el vector para cada publicación.
Limito el tamaño de cada vector al usar como características las palabras usadas con mayor frecuencia (k = número) (no se usarán palabras vacías)
Vectorexample_with_k_8 = [0,0,0,1,0,3,0,0]
Mis datos son generalmente escasos como en el ejemplo.
Cuando pruebo el modelo en los datos de mi prueba obtengo un puntaje r² muy bajo (0.00-0.1), a veces incluso un puntaje negativo. El modelo predice siempre la misma edad, que es la edad promedio de mi conjunto de datos, como se ve en la distribución de mis datos (edad / cantidad):
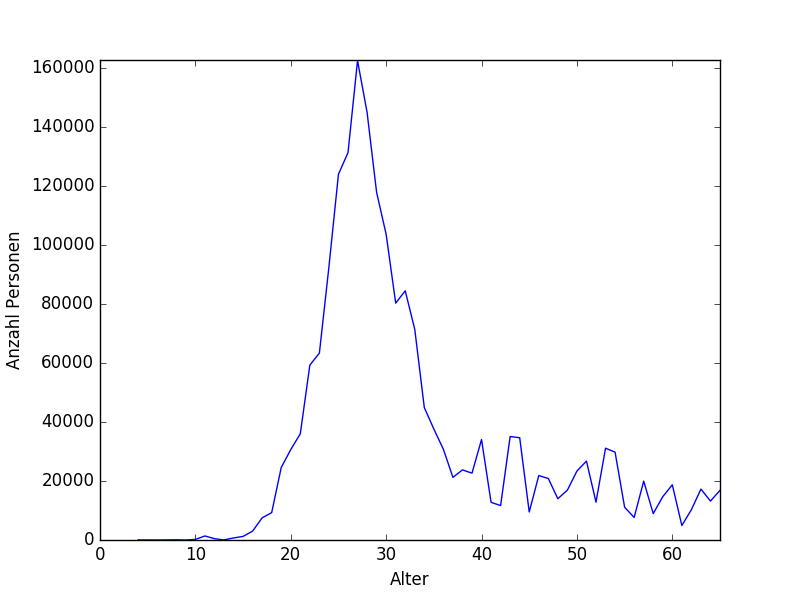
Utilicé diferentes modelos de regresión: Regresión lineal, Lazo, SGDRegressor de scikit-learn sin ninguna mejora.
Entonces las preguntas son:
1.¿Cómo mejoro el puntaje r²?
¿Tengo que cambiar los datos para que se ajusten mejor a la regresión? En caso afirmativo con qué método?
3. ¿Qué regresor / métodos debo usar para la clasificación de texto?