Comparando Python, Numpy, Numba y C ++ para la multiplicación de matrices
En un programa en el que estoy trabajando, necesito multiplicar dos matrices repetidamente. Debido al tamaño de una de las matrices, esta operación lleva algún tiempo y quería ver qué método sería el más eficiente. Las matrices tienen dimensiones.(m x n)*(n x p) dóndem = n = 3 y10^5 < p < 10^6.
Con la excepción de Numpy, que supongo que funciona con un algoritmo optimizado, cada prueba consiste en una implementación simple demultiplicación de matrices:

A continuación se encuentran mis diversas implementaciones:
Pitón
def dot_py(A,B):
m, n = A.shape
p = B.shape[1]
C = np.zeros((m,p))
for i in range(0,m):
for j in range(0,p):
for k in range(0,n):
C[i,j] += A[i,k]*B[k,j]
return C
Numpy
def dot_np(A,B):
C = np.dot(A,B)
return C
Numba
El código es el mismo que el de Python, pero se compila justo a tiempo antes de usarse:
dot_nb = nb.jit(nb.float64[:,:](nb.float64[:,:], nb.float64[:,:]), nopython = True)(dot_py)
Hasta ahora, cada llamada al método se ha cronometrado utilizando eltimeit Módulo 10 veces. El mejor resultado se mantiene. Las matrices se crean usandonp.random.rand(n,m).
C ++
mat2 dot(const mat2& m1, const mat2& m2)
{
int m = m1.rows_;
int n = m1.cols_;
int p = m2.cols_;
mat2 m3(m,p);
for (int row = 0; row < m; row++) {
for (int col = 0; col < p; col++) {
for (int k = 0; k < n; k++) {
m3.data_[p*row + col] += m1.data_[n*row + k]*m2.data_[p*k + col];
}
}
}
return m3;
}
Aquí,mat2 es una clase personalizada que definí ydot(const mat2& m1, const mat2& m2) es una función amiga para esta clase. Se cronometra usandoQPF yQPC deWindows.h y el programa se compila utilizando MinGW con elg++ mando. Nuevamente, se mantiene el mejor tiempo obtenido de 10 ejecuciones.
Resultados
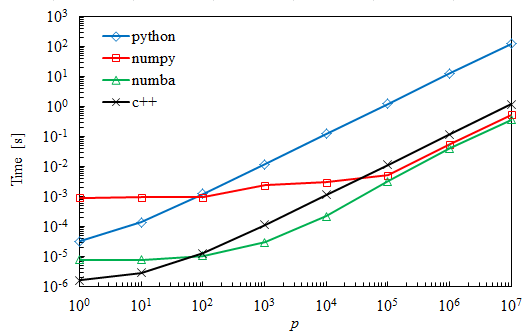
Como se esperaba, el código simple de Python es más lento pero aún supera a Numpy por matrices muy pequeñas. Numba resulta ser aproximadamente un 30% más rápido que Numpy para los casos más grandes.
Estoy sorprendido con los resultados de C ++, donde la multiplicación toma casi un orden de magnitud más tiempo que con Numba. De hecho, esperaba que tomaran una cantidad de tiempo similar.
Esto me lleva a mi pregunta principal: ¿es esto normal? Si no, ¿por qué C ++ es más lento que Numba? Acabo de comenzar a aprender C ++, por lo que podría estar haciendo algo mal. Si es así, ¿cuál sería mi error o qué podría hacer para mejorar la eficiencia de mi código (aparte de elegir un algoritmo mejor)?
EDITAR 1
Aquí está el encabezado de lamat2 clase.
#ifndef MAT2_H
#define MAT2_H
#include <iostream>
class mat2
{
private:
int rows_, cols_;
float* data_;
public:
mat2() {} // (default) constructor
mat2(int rows, int cols, float value = 0); // constructor
mat2(const mat2& other); // copy constructor
~mat2(); // destructor
// Operators
mat2& operator=(mat2 other); // assignment operator
float operator()(int row, int col) const;
float& operator() (int row, int col);
mat2 operator*(const mat2& other);
// Operations
friend mat2 dot(const mat2& m1, const mat2& m2);
// Other
friend void swap(mat2& first, mat2& second);
friend std::ostream& operator<<(std::ostream& os, const mat2& M);
};
#endif
Editar 2
Como muchos sugirieron, usar el indicador de optimización era el elemento que faltaba para coincidir con Numba. A continuación se muestran las nuevas curvas en comparación con las anteriores. La curva etiquetadav2 se obtuvo cambiando los dos bucles internos y muestra otra mejora del 30% al 50%.
