Agregación completa de SPARQL en una agregación grupal
Tengo una ontología donde los usuarios pueden usar uno de los cinco predicados para expresar cuánto les gusta un artículo.
La ontología contiene predicados específicos que tienen una propiedad llamada hasSimilarityValue.
Estoy tratando de hacer lo siguiente:
Tener un usuario digamos rs: aniaExtraiga todos los elementos que este usuario haya calificado anteriormente. (esto es fácil porque la ontología ya contiene el triple del usuario a los elementos)Extraiga elementos similares a los elementos que se extrajeron en el paso 2 y calcule sus similitudes. (Aquí estamos utilizando nuestro propio enfoque para calcular las similitudes). Sin embargo, el problema es: desde el paso 2, tenemos muchos elementos que el usuario ha calificado, desde el paso allí estamos extrayendo y calculando elementos similares a estos elementos que vinieron del paso 2. Entonces, es posible que un elemento en el paso 3 sea similar a dos (o más) elementos del paso 2. Por lo tanto, terminamos con lo siguiente:
usuario: elemento calificado ania x1 usuario: elemento calificado ania x2 elemento y es similar por y1 a x1 elemento y es similar por y2 a x2 elemento z es similar por z1 a x1
y1, y2 y z1 son valores entre 0 y 1
La cuestión es que necesitamos normalizar estos valores para conocer las similitudes finales para el elemento y el elemento z.
la normalización es simple, solo agrupe por elemento y divida pornúmero máximo de artículos
para conocer la similitud con y, debería hacer (y1 + y2 / 2)
para conocer la similitud con z, debería hacer (z1 / 2)
mi problema
como ves, necesito contar los artículos y luego saber el máximo de este recuento
esta es la consulta que calcula todosin la parte de normalización
select ?s (sum(?weight * ?factor) as ?similarity) ( sum(?weight * ?factor * ?ratings) as ?similarityWithRating) (count(distinct ?x) as ?countOfItemsUsedInDeterminingTheSimilarities) where {
values (?user) { (rs:ania) }
values (?ratingPredict) {(rs:ratedBy4Stars) (rs:ratedBy5Stars)}
?user ?ratingPredict ?x.
?ratingPredict rs:hasRatingValue ?ratings.
{
?s ?p ?o .
?x ?p ?o .
bind(4/7 as ?weight)
}
union
{
?s ?a ?b . ?b ?p ?o .
?x ?c ?d . ?d ?p ?o .
bind(1/7 as ?weight)
}
?p rs:hasSimilarityValue ?factor .
filter (?s != ?x)
}
group by ?s
order by ?s
el resultado es:
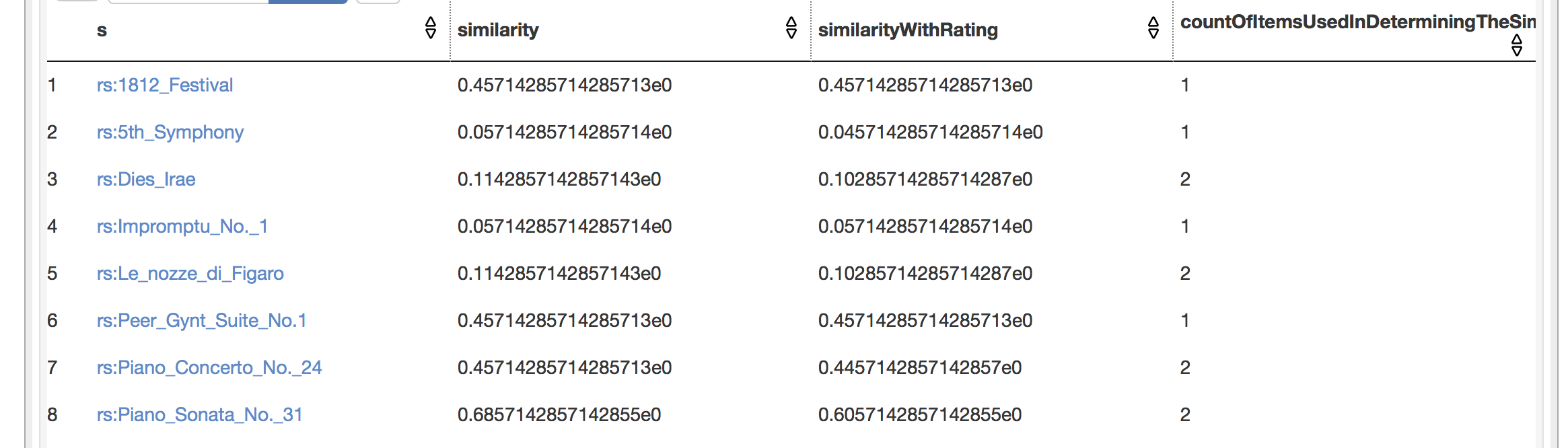
ahora necesito dividir cada fila por el máximo de la columna de conteo,
mi solución propuesta es repetir la consulta exacta dos veces, una para obtener las similitudes y otra para obtener el máximo y luego unirlas y luego hacer la división (normalización). está funcionando pero es feo, el rendimiento será un desastre porque estoy repitiendo la misma consulta dos veces. es una estúpida solución y me gustaría pedirles una mejor por favor
Aquí están mis soluciones estúpidas
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX rs: <http://www.musicontology.com/rs#>
PREFIX pdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
#select
#?s ?similarityWithRating (max(?countOfItemsUsedInDeterminingTheSimilarities) as ?maxNumberOfItemsUsedInDeterminingTheSimilarities)
#where {
# {
select ?s ?similarity ?similarityWithRating ?countOfItemsUsedInDeterminingTheSimilarities ?maxCountOfItemsUsedInDeterminingTheSimilarities ?finalSimilarity where {
{
select ?s (sum(?weight * ?factor) as ?similarity) ( sum(?weight * ?factor * ?ratings) as ?similarityWithRating) (count(distinct ?x) as ?countOfItemsUsedInDeterminingTheSimilarities) where {
values (?user) { (rs:ania) }
values (?ratingPredict) {(rs:ratedBy4Stars) (rs:ratedBy5Stars)}
?user ?ratingPredict ?x.
?ratingPredict rs:hasRatingValue ?ratings.
{
?s ?p ?o .
?x ?p ?o .
bind(4/7 as ?weight)
}
union
{
?s ?a ?b . ?b ?p ?o .
?x ?c ?d . ?d ?p ?o .
bind(1/7 as ?weight)
}
?p rs:hasSimilarityValue ?factor .
filter (?s != ?x)
}
group by ?s
#}
#}
#group by ?s
order by ?s
} #end first part
{
select (Max(?countOfItemsUsedInDeterminingTheSimilarities) as ?maxCountOfItemsUsedInDeterminingTheSimilarities) where {
select ?s (sum(?weight * ?factor) as ?similarity) ( sum(?weight * ?factor * ?ratings) as ?similarityWithRating) (count(distinct ?x) as ?countOfItemsUsedInDeterminingTheSimilarities) where {
values (?user) { (rs:ania) }
values (?ratingPredict) {(rs:ratedBy4Stars) (rs:ratedBy5Stars)}
?user ?ratingPredict ?x.
?ratingPredict rs:hasRatingValue ?ratings.
{
?s ?p ?o .
?x ?p ?o .
bind(4/7 as ?weight)
}
union
{
?s ?a ?b . ?b ?p ?o .
?x ?c ?d . ?d ?p ?o .
bind(1/7 as ?weight)
}
?p rs:hasSimilarityValue ?factor .
filter (?s != ?x)
}
group by ?s
#}
#}
#group by ?s
order by ?s
}
}#end second part
bind (?similarityWithRating/?maxCountOfItemsUsedInDeterminingTheSimilarities as ?finalSimilarity)
}
order by desc(?finalSimilarity)
Aquí están los datos si quieres probarlo tú mismo.http://www.mediafire.com/view/r4qlu3uxijs4y30/musicontology