Полная агрегация SPARQL по групповой агрегации
У меня есть Онтология, где пользователи могут использовать один из пяти предикатов, чтобы выразить, насколько им нравится элемент.
Онтология содержит конкретные предикаты, которые имеют свойство hasSimilityValue.
Я пытаюсь сделать следующее:
Имея пользователя, скажем, rs: aniaИзвлеките все предметы, которые этот пользователь оценил ранее. (это легко, потому что онтология уже содержит тройку от пользователя до предметов)Извлеките одинаковые предметы из предметов, которые были извлечены на шаге 2, и вычислите их сходство. (здесь мы используем наш собственный подход для расчета похожих объектов). Однако проблема заключается в том, что на шаге 2 у нас есть много элементов, которые пользователь оценил, на шаге мы извлекаем и вычисляем элементы, аналогичные этим элементам, полученным на шаге 2. Таким образом, возможно, что элемент на шаге 3 похож до двух (или более) элементов из шага 2. Таким образом, мы получаем следующее:
пользователь: предмет с оценкой ania x1 пользователь: предмет с оценкой ania x2 элемент y похож на y1 на x1 элемент y похож на y2 на x2 элемент z похож на z1 на x1
y1, y2 и z1 являются значениями от 0 до 1
Дело в том, что нам нужно нормализовать эти значения, чтобы узнать окончательное сходство для элемента y и элемента z.
нормализация проста, просто сгруппировать по элементам и разделить намаксимальное количество предметов
поэтому, чтобы узнать сходство с у, я должен сделать (у1 + у2 / 2)
чтобы узнать сходство с z, я должен сделать (z1 / 2)
моя проблема
как вы видите, мне нужно посчитать предметы, а затем узнать максимум этого количества
это запрос, который вычисляет всебез нормализации
select ?s (sum(?weight * ?factor) as ?similarity) ( sum(?weight * ?factor * ?ratings) as ?similarityWithRating) (count(distinct ?x) as ?countOfItemsUsedInDeterminingTheSimilarities) where {
values (?user) { (rs:ania) }
values (?ratingPredict) {(rs:ratedBy4Stars) (rs:ratedBy5Stars)}
?user ?ratingPredict ?x.
?ratingPredict rs:hasRatingValue ?ratings.
{
?s ?p ?o .
?x ?p ?o .
bind(4/7 as ?weight)
}
union
{
?s ?a ?b . ?b ?p ?o .
?x ?c ?d . ?d ?p ?o .
bind(1/7 as ?weight)
}
?p rs:hasSimilarityValue ?factor .
filter (?s != ?x)
}
group by ?s
order by ?s
результат:
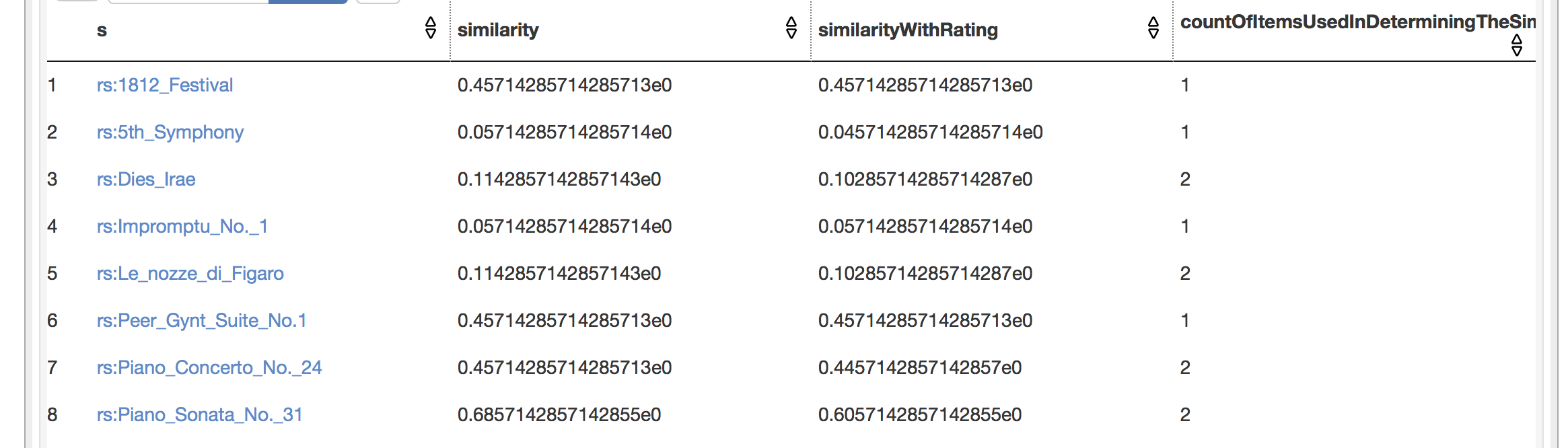
теперь мне нужно разделить каждую строку на максимум столбца count,
Мое предлагаемое решение состоит в том, чтобы повторить точный запрос дважды, один раз, чтобы получить сходства, и один раз, чтобы получить максимум, а затем соединить их и затем выполнить деление (нормализация). это работает, но это ужасно, производительность будет катастрофической, потому что я повторяю один и тот же запрос дважды. это глупое решение, и я хотел бы попросить вас, ребята, для лучшего, пожалуйста
вот мои глупые решения
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX rs: <http://www.musicontology.com/rs#>
PREFIX pdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
#select
#?s ?similarityWithRating (max(?countOfItemsUsedInDeterminingTheSimilarities) as ?maxNumberOfItemsUsedInDeterminingTheSimilarities)
#where {
# {
select ?s ?similarity ?similarityWithRating ?countOfItemsUsedInDeterminingTheSimilarities ?maxCountOfItemsUsedInDeterminingTheSimilarities ?finalSimilarity where {
{
select ?s (sum(?weight * ?factor) as ?similarity) ( sum(?weight * ?factor * ?ratings) as ?similarityWithRating) (count(distinct ?x) as ?countOfItemsUsedInDeterminingTheSimilarities) where {
values (?user) { (rs:ania) }
values (?ratingPredict) {(rs:ratedBy4Stars) (rs:ratedBy5Stars)}
?user ?ratingPredict ?x.
?ratingPredict rs:hasRatingValue ?ratings.
{
?s ?p ?o .
?x ?p ?o .
bind(4/7 as ?weight)
}
union
{
?s ?a ?b . ?b ?p ?o .
?x ?c ?d . ?d ?p ?o .
bind(1/7 as ?weight)
}
?p rs:hasSimilarityValue ?factor .
filter (?s != ?x)
}
group by ?s
#}
#}
#group by ?s
order by ?s
} #end first part
{
select (Max(?countOfItemsUsedInDeterminingTheSimilarities) as ?maxCountOfItemsUsedInDeterminingTheSimilarities) where {
select ?s (sum(?weight * ?factor) as ?similarity) ( sum(?weight * ?factor * ?ratings) as ?similarityWithRating) (count(distinct ?x) as ?countOfItemsUsedInDeterminingTheSimilarities) where {
values (?user) { (rs:ania) }
values (?ratingPredict) {(rs:ratedBy4Stars) (rs:ratedBy5Stars)}
?user ?ratingPredict ?x.
?ratingPredict rs:hasRatingValue ?ratings.
{
?s ?p ?o .
?x ?p ?o .
bind(4/7 as ?weight)
}
union
{
?s ?a ?b . ?b ?p ?o .
?x ?c ?d . ?d ?p ?o .
bind(1/7 as ?weight)
}
?p rs:hasSimilarityValue ?factor .
filter (?s != ?x)
}
group by ?s
#}
#}
#group by ?s
order by ?s
}
}#end second part
bind (?similarityWithRating/?maxCountOfItemsUsedInDeterminingTheSimilarities as ?finalSimilarity)
}
order by desc(?finalSimilarity)
Вот данные, если вы хотите попробовать сами.http://www.mediafire.com/view/r4qlu3uxijs4y30/musicontology