Почему мне не удается перекрыть передачу данных и вычисления с GTX 480 и CUDA 5?
Я пытался перекрывать выполнение ядра с помощью memcpyasync, но это нет работа. Я следую всем рекомендациям в руководстве по программированию, используя закрепленную память, различные потоки и т. Д. Я вижу, что выполнение ядра перекрывается, но это не такт с мемо передачи. Я знаю, что у моей карты есть только один механизм копирования и один механизм выполнения, но выполнение и передача должны перекрываться, верно?
Похоже на токопировальный движок " а также "двигатель исполнения " всегда следите за порядком, который я называю функциями. Работа состоит из 4 потоков, выполняющих [HtoD x2, Kernel, DtoH]. Если я выдаю серию HtoDx2, Kernel, DtoH для каждого потока, я вижу в профилировщике, как первая операция stream2 HtoD не начнется, пока не закончится первая операция DtoH. Если я выдаю сначала HtoD для каждого потока, затем второе HtoD, затем ядро, а затем DtoH (ширина), я не вижу перекрытия, и порядок выдачи также обеспечивается GPU.
Я попытался с примером simpleStreams, приведенным в CUDA SDK, и я также вижу то же поведение.
Я прилагаю некоторые снимки экрана, показывающие проблему в визуальном профилировщике и Nsight для VS2008.
пс. Я неt установил CUDA_LAUNCH_BLOCKING env
Simple Streams Visual Profiler 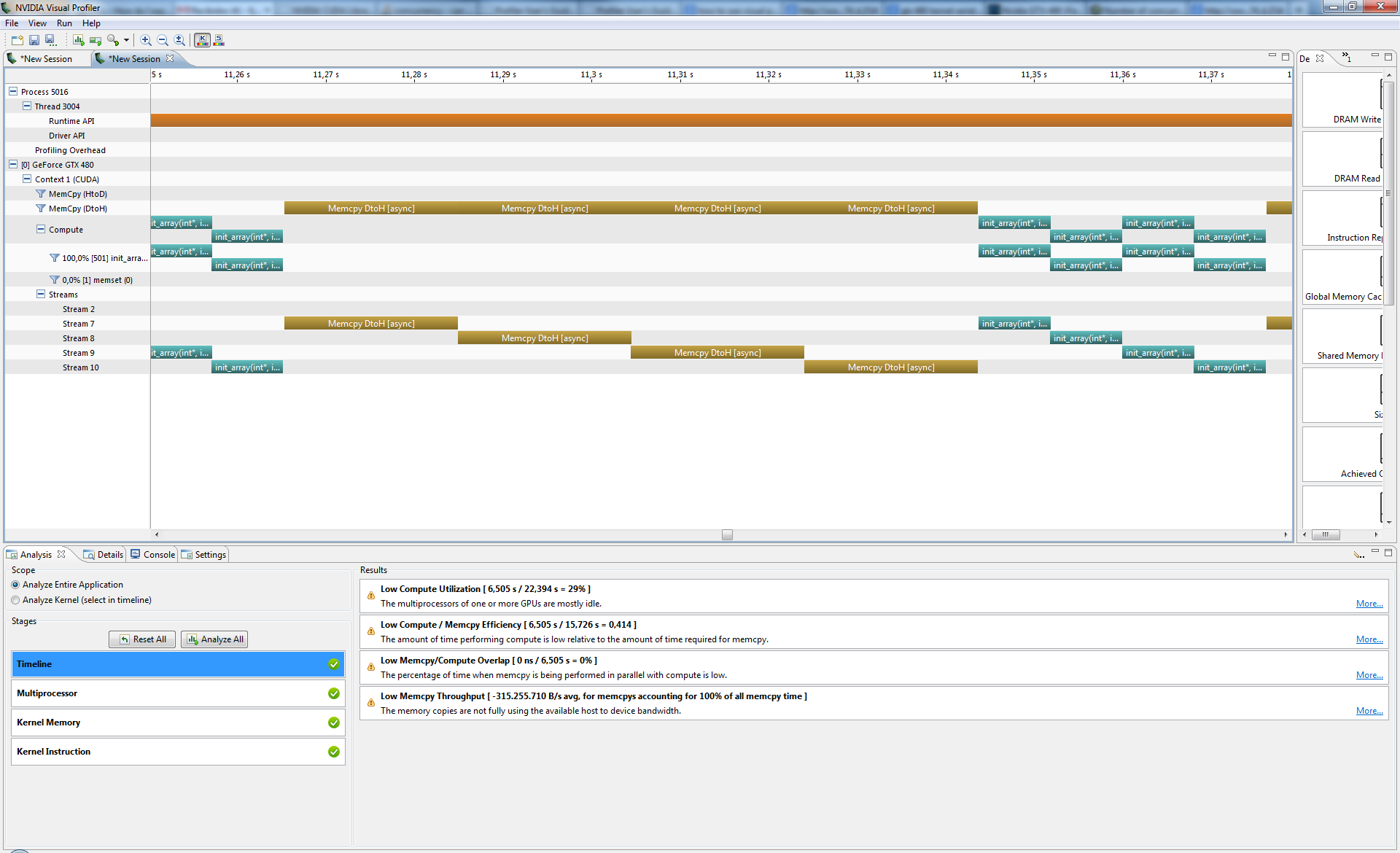
Временная шкала MyApp Nsight в первую очередь 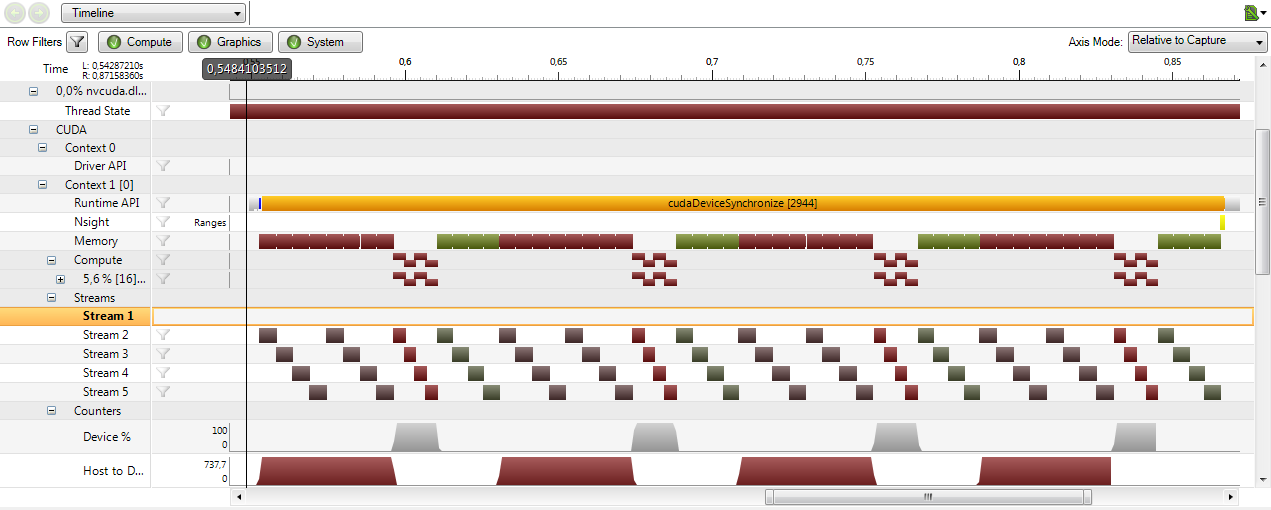
MyApp Nsight шкала глубины первой 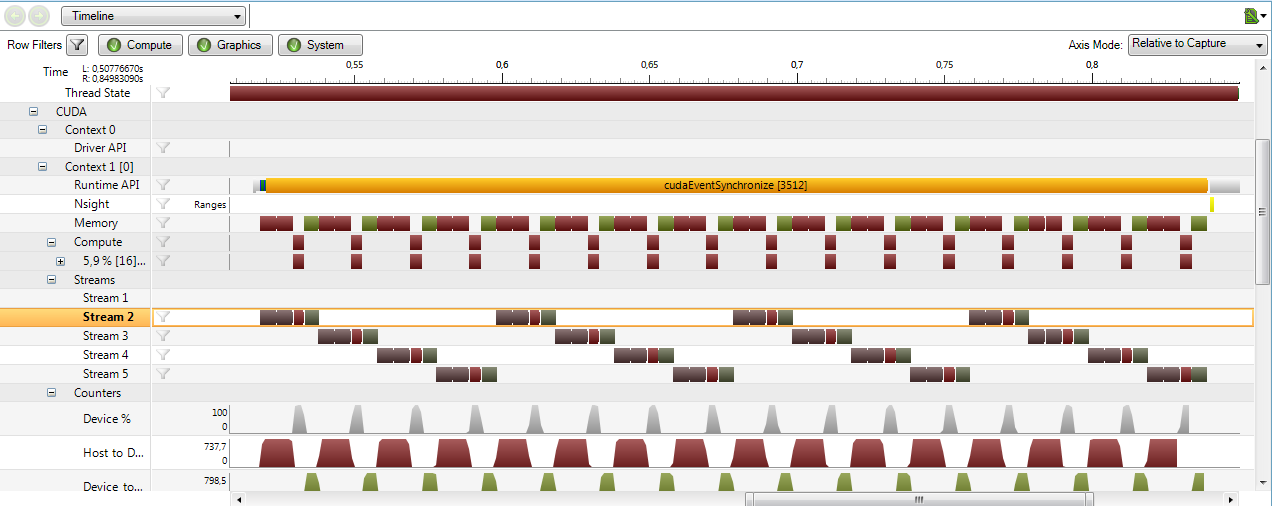
редактировать:
добавление дополнительных ядер x4 (всего 2HtoD, 5 ядер, 1DtoH на поток) -> Если я запускаю nvprof с и без --concurrent-kernels-off, истекшее время одинаково. Если я установлю env CUDA_LAUNCH_BLOCKING = 1, то я вижу улучшение производительности (из командной строки) на 7,5%!
Спецификация системы:
Windows 7NVIDIA 6800 VGA в первом слоте PCI-EGTX480 во втором слоте PCI-EДрайвер NVIDIA: 306,94Визуальная студия 2008CUDA v5.0Visual Profiler 5.0Nsight 3.0