Но это реализация тензорного потока с использованием этих алгоритмов или нет?
уПрограмма сравнения строк на основе GPU с использованием расстояния редактирования с помощью tenorflow функции. Зная соответствующую часть, я извлеку детали, а затем сохраню их в таблице данных, которая в конечном итоге будет сохранена в виде файла CSV. Вот подробности:
У меня есть 2 списка.меньший список называетсяtest_string который содержит около9 слов,больше называетсяref_string который в основном разбивает большой текстовый файл на одно слово в строке. Файл изначально былпара ключ-значение, Поэтому при разделении ключ будет находиться в одной строке, а значение будет в следующей строке.
Я используюmuliprocessing / joblib впараллельное чтение файлы и передать список чтения в качестве списка ref_string, где сравнение расстояний редактирования выполняется в gpu.
Всего4080 текстовых файлов и каждый текстовый файл содержит около10000 слов когда разделен.
Используя расстояние редактирования tf, каждое слово сопоставляется с ref_words.индекс гдередактировать расстояние становитсянуль отмечается, а затем(index+1) используется для извлечения его значения.
Спецификация системы: Intel Core i5, оперативная память 12 ГБ, Nvidia 940mx с 2 ГБ, Tensorflow 1.10.0, Cuda 9.0, Cudnn 7.1.
Аналогичная программа, которую я сделал здесь с использованием cpu, и я хотел посмотреть, может ли использование gpu ускорить время выполнения, которое можно найтиВот.
Вот небольшой фрагмент кода:
def main_prog(filenames):
try:
with open(path+filenames,'r') as f:
ref_string=f.readlines()
ref_string=[x.strip() for x in ref_string]
index=slicer(ref_string)
ref_string=ref_string[index[0]:(index[1]-1)]
for i in range(0,len(test_string)):
test_string1=test_string[i]
out=[x==test_string1 for x in ref_string]
out=[i for i, x in enumerate(out) if x]
if len(out)!=0:
# Comparing the data using tf with edit distance
with tf.Session(config=tf.ConfigProto(intra_op_parallelism_threads=10)) as sess:
test_string_sparse = create_sparse_vec(filler(test_string1,ref_string))
ref_string_sparse = create_sparse_vec(ref_string)
out=get_index(sess.run(tf.edit_distance(test_string_sparse, ref_string_sparse, normalize=True)))
df.set_value(0,test_string1,ref_string[out+1])
else:
df.set_value(0,test_string1,"nil")
return df
except:
return df
if __name__ == '__main__':
test_string=["name","Price","oPrice","discount","brand","id","seller","id","category"]
df=pd.DataFrame(columns=test_string)
filenames=os.listdir("/home/Desktop/Parallelise/mod_all_page/")
data=df.append((Parallel(n_jobs=2)(delayed(main_prog)(filenames[i]) for i in range(100))),ignore_index=True)
data.to_csv("/home/Desktop/final_out.csv")
Код работает, но он очень медленный, Я вижу среднюю загрузку процессора около 80-90%. При проверке состояния nvidia-smi было запущено 2 задания, и одно из них потребляло около 1,9 ГБ. После иногда программа вылетает из-за сбоя памяти. При тестировании около 100 входных файлов время выполнения составляет около 70 секунд, а код версии процессора извлекает 4080 файлов за 18 секунд.
Версия графического процессора (tenorflow-gpu) 100 входных файлов: 70 сек.Версия процессора (многопроцессорная) 4080 входных файлов: 18 сек.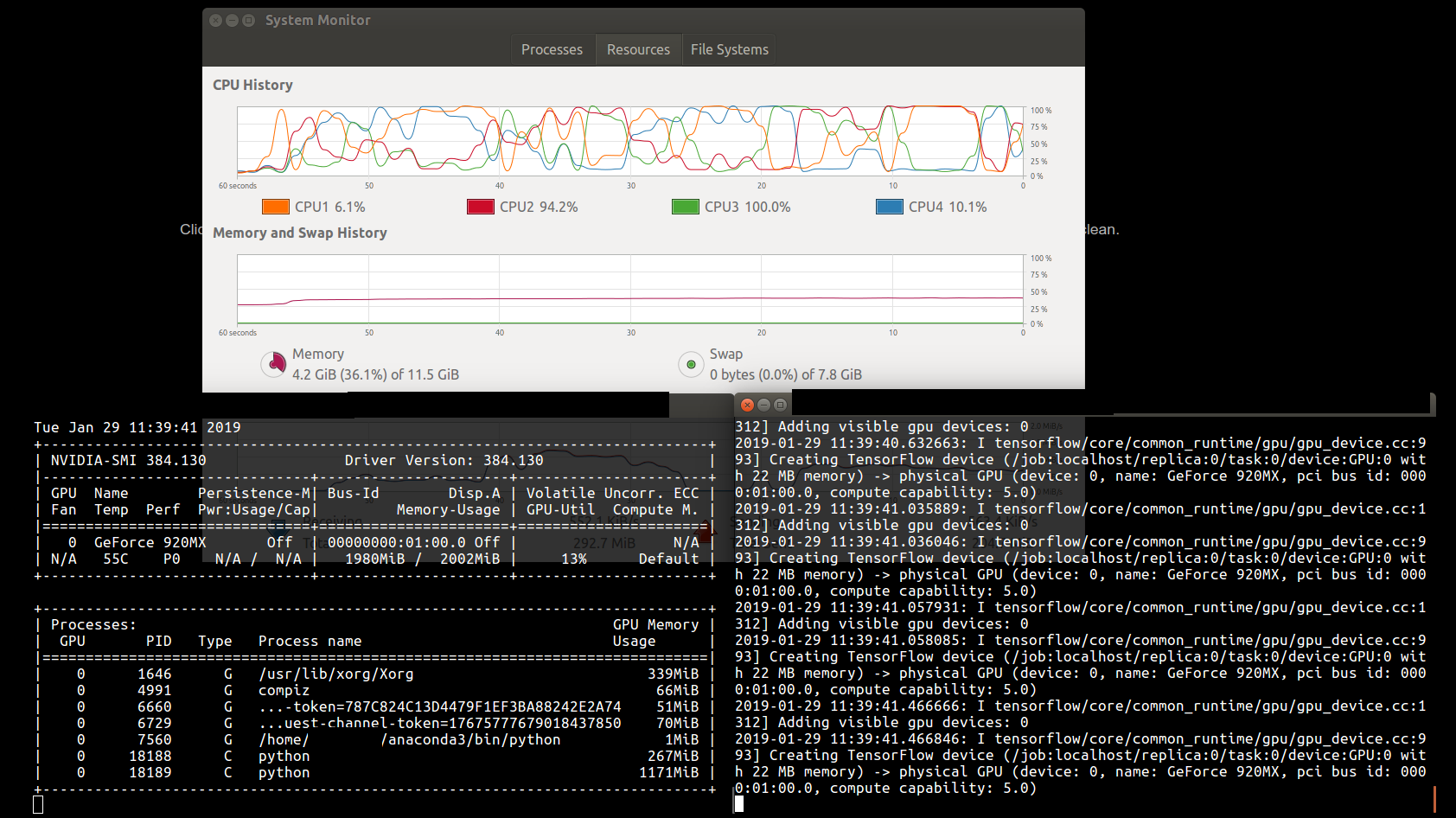
Что-то не так с кодом? Могу ли я сделать это быстрее? Я пытался с помощью Google Colab получить доступ к Tesla GPU, так как он имеет большой оперативной памяти, но тем не менее, производительность остается той же. Код где-то не оптимизирован. Я попробую сделать профилирование и выложу обновление.
Если кто-то может указать, где я допустил ошибку, это было бы очень полезно. Спасибо!
Обновить:Мне удалось сократить время выполнения 100 файлов с 70 до 8 секунд, увеличив число n_jobs до 4. Но это выдает ошибку «CUDA out of memory» при попытке выполнить то же самое для большого набора данных, такого как 4080 файлов.