Я буду +1 ваш запрос в качестве особого требования. Пожалуйста, следите за последними анонсами AppSync в будущем.
онравилось работать сAWS Amplify в последнее время его генерация кода для запросов GraphQL на основе определенной схемы является выдающейся.
Я столкнулся с одной сложностью для определения пользовательской логики / проверки на стороне сервера. Из сумкиAppSync (часть, ответственная за API GraphQL в Amplify) генерирует преобразователи и таблицы DynamoDB для вашей схемы. Резольверы создаются с использованиемApache Velocity язык шаблонов, и если вы новичок в этом, это немного кривая обучения, на мой взгляд.
Кроме того, эти резольверы автоматически генерируются Amplify cli. Я не уверен, имеет ли смысл их редактирование в консоли AppSync или локально, поскольку каждый раз, когда мы вносим изменения в API, они автоматически генерируются снова?
Чтобы добавить к этому, эти распознаватели, которые автоматически генерируются, на самом деле многого достигают с точки зрения объединения моделей типов, включая поиск и проверки подлинности, я действительно не хочу касаться их, так как скорость разработки, включаемая автоматической генерацией, безумна.
Следовательно, только другое решение для введения моей пользовательской логики - это лямбда-функции, которые прослушивают события создания / обновления связанных таблиц DynamoDB.
Я думаю, что могу настроить это так, как показано ниже, по сути, позволяя пользователям использовать GraphQL api нормально, и когда действие, которое требует проверки сервера, будет выполнено, реагировать на него в лямбда-выражении?
Например, игрок добавляет предмет в свой инвентарь, мы запускаем лямбда-функцию, чтобы проверить, был ли у игрока этот предмет раньше, если он не был приобретен, мы проверяем данные предмета и вычитаем золото его стоимости из таблицы игрока. Я думаю, что это работает нормально, но мои опасения
Мы разрешаем сначала записывать непроверенные данные в базу данных (хотя это проверяется системой типов graphql и проверкой аутентификации).Дополнительные затраты на привлечение Lambda (на мой взгляд, стоит сэкономить время и возможность использовать NodeJS вместо Apache Velocity для определения языка)Я что-то упустил?
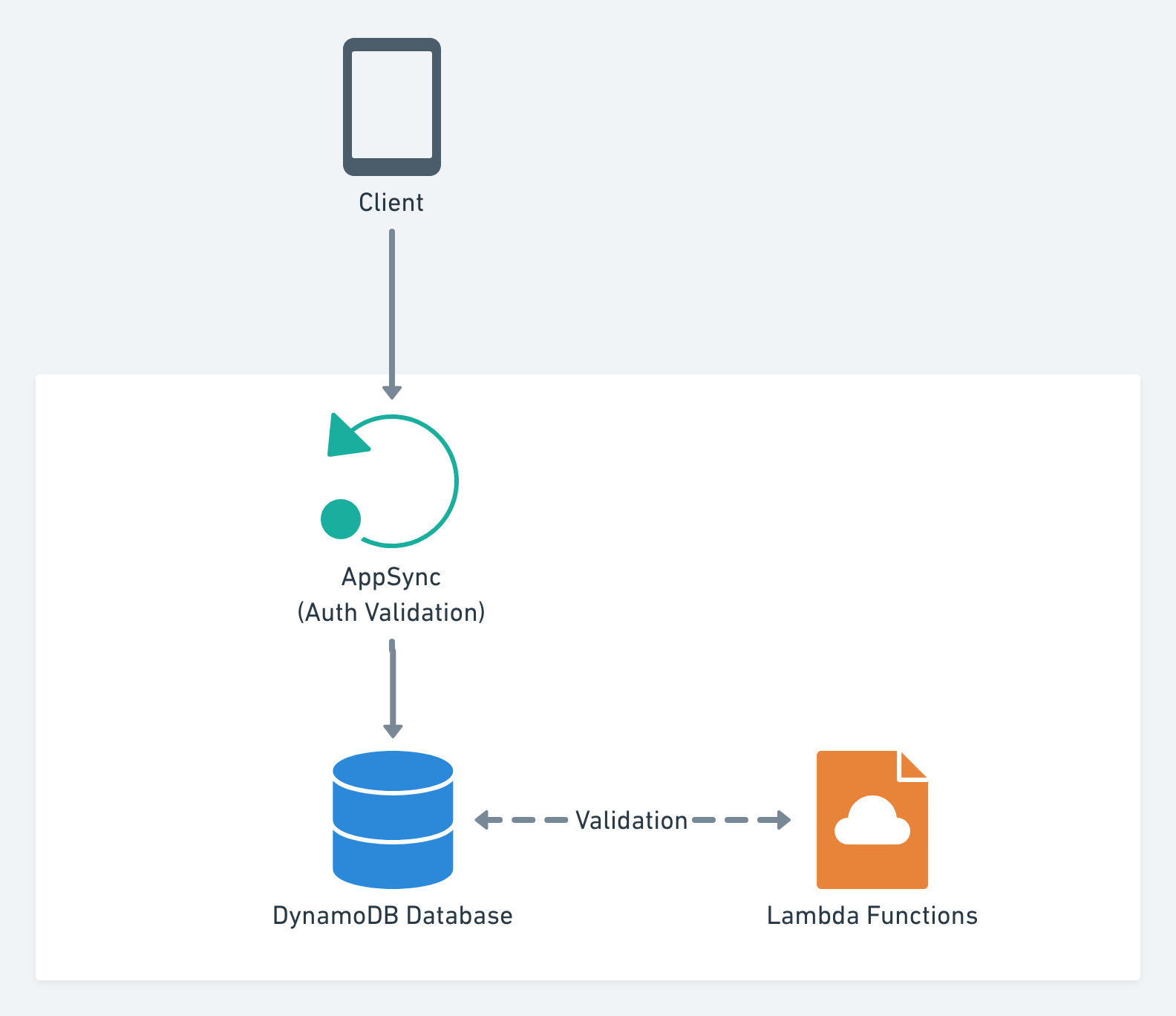
Таким образом, лямбда выполнит валидацию за кулисами, мы предполагаем, что большинство пользователей здесь хорошие актеры, и данные, которые они передают в GraphQL api, верны, поскольку они используют наш клиент.
Если данные неожиданные (плохой актер), лямбда отреагирует и забанит пользователя.
Является ли это решение жизнеспособным / общим, есть ли другая альтернатива?