Следует отметить, что если тип данных назначен только обязательным полям, то результирующий кадр данных будет содержать только те поля, которые были изменены.
я есть датафрейм в pyspark. Некоторые из его числовых столбцов содержат 'nan', поэтому, когда я читаю данные и проверяю схему dataframe, эти столбцы будут иметь тип 'string'. Как я могу изменить их на тип int. Я заменил значения 'nan' на 0 и снова проверил схему, но затем он также показывает тип строки для этих столбцов. Я следую приведенному ниже коду:
data_df = sqlContext.read.format("csv").load('data.csv',header=True, inferSchema="true")
data_df.printSchema()
data_df = data_df.fillna(0)
data_df.printSchema()
мои данные выглядят так:
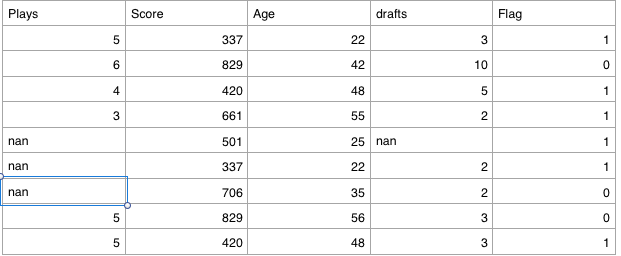
здесь столбцы «Воспроизведение» и «черновики», содержащие целочисленные значения, но из-за того, что в этих столбцах присутствует nan, они рассматриваются как строковый тип.