@ Рубен Спасибо за редактирование.
ел бы получить данные с этого сайта:https://finviz.com/screener.ashx?v=141&f=sh_avgvol_o500,sh_curvol_o2000,sh_price_u50&o=-volume
Я хочу очистить весь стол. Я пытался использовать это:
function myFunction(start) {
var url = "https://finviz.com/screener.ashx?
v=141&f=sh_avgvol_o500,sh_curvol_o2000,sh_price_u50&o=-volume&r="+
start;
var fromText = '<tbody>';
var toText = '</tbody>';
var content = UrlFetchApp.fetch(url).getContentText();
var scraped = Parser
.data(content)
.from(fromText)
.to(toText)
.iterate();
}
Я мог очистить каждый элемент с помощью xpath, но я думаю, что это будет довольно медленно.
Вот HTML и таблица:
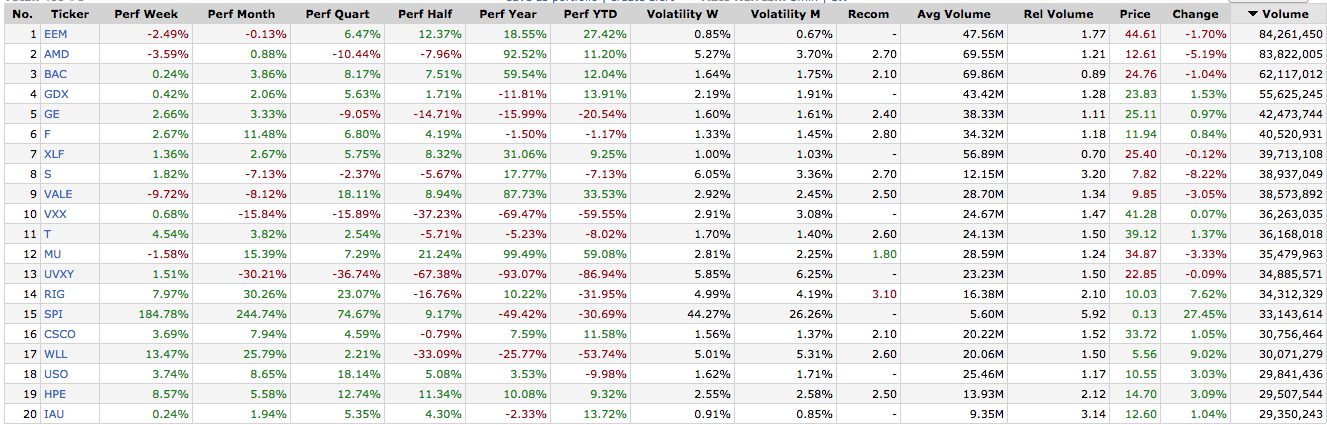
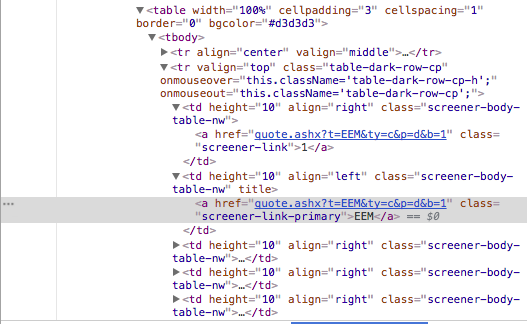
Могу ли я получить всю таблицу? Спасибо