этот цикл для половины регистра. Практически каждая инструкция AVX2 работает на все 8 поплавков.
я есть эта функция:
bool interpolate(const Mat &im, float ofsx, float ofsy, float a11, float a12, float a21, float a22, Mat &res)
{
bool ret = false;
// input size (-1 for the safe bilinear interpolation)
const int width = im.cols-1;
const int height = im.rows-1;
// output size
const int halfWidth = res.cols >> 1;
const int halfHeight = res.rows >> 1;
float *out = res.ptr<float>(0);
const float *imptr = im.ptr<float>(0);
for (int j=-halfHeight; j<=halfHeight; ++j)
{
const float rx = ofsx + j * a12;
const float ry = ofsy + j * a22;
#pragma omp simd
for(int i=-halfWidth; i<=halfWidth; ++i, out++)
{
float wx = rx + i * a11;
float wy = ry + i * a21;
const int x = (int) floor(wx);
const int y = (int) floor(wy);
if (x >= 0 && y >= 0 && x < width && y < height)
{
// compute weights
wx -= x; wy -= y;
int rowOffset = y*im.cols;
int rowOffset1 = (y+1)*im.cols;
// bilinear interpolation
*out =
(1.0f - wy) * ((1.0f - wx) * imptr[rowOffset+x] + wx * imptr[rowOffset+x+1]) +
( wy) * ((1.0f - wx) * imptr[rowOffset1+x] + wx * imptr[rowOffset1+x+1]);
} else {
, *out = 0;
ret = true; // touching boundary of the input
}
}
}
return ret;
}
halfWidth очень случайный: это может быть 9, 84, 20, 95, 111 ... Я только пытаюсь оптимизировать этот код, я не понимаю его в деталях.
Как видите, внутреннийfor уже векторизовано, но Intel Advisor предлагает следующее:
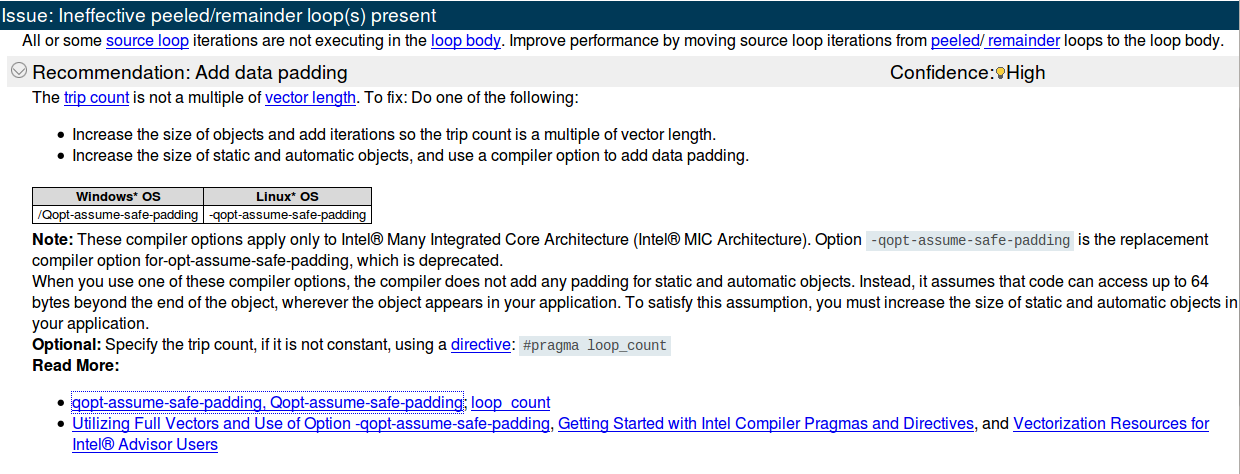
И это результат анализа счетчика поездок:

Насколько я понимаю, это означает, что:
Длина вектора равна 8, поэтому это означает, что 8 операций с плавающей запятой могут обрабатываться одновременно для каждого цикла. Это будет означать (если я не ошибаюсь), что данные выровнены по 32 байта (даже если я объяснюВот кажется, что компилятор считает, что данные не выровнены).В среднем 2 цикла полностью векторизованы, а 3 цикла являются остаточными циклами. То же самое касается Мин и Макс. В противном случае я не понимаю, что; средства.Теперь мой вопрос: как я могу последовать первому предложению Intel Advisor? В нем говорится «увеличить размер объектов и добавить итерации, чтобы количество поездок было кратно длине вектора». Хорошо, просто сказано: «Эй, парень, сделай это такhalfWidth*2+1 (так как идет от-halfWidth в+halfWidth кратно 8) ". Но как я могу это сделать? Если я добавлю случайные циклы, это, очевидно, нарушит алгоритм!
Единственное решение, которое пришло мне в голову, это добавить «фальшивые» итерации, подобные этой:
const int vectorLength = 8;
const int iterations = halfWidth*2+1;
const int remainder = iterations%vectorLength;
for(int i=0; i<loop+length-remainder; i++){
//this iteration was not supposed to exist, skip it!
if(i>halfWidth)
continue;
}
Конечно, этот код не будет работать, так как он идет от-halfWidth вhalfWidth, но это чтобы вы поняли мою стратегию «фальшивых» итераций.
Что касается второго варианта («Увеличьте размер статических и автоматических объектов и используйте опцию компилятора для добавления заполнения данных»), я понятия не имею, как это реализовать.