Обратите внимание, что второе изображение пропускает 1: col1, 2: col2, 1: col2 и 2: col2
у запустить многочленный логит в R и использовал две библиотеки,nnet а такжеmlogit, которые дают разные результаты и сообщают о различных видах статистики. Мои вопросы:
Каков источник несоответствия между коэффициентами и стандартными ошибками, о которых сообщаетnnet и те, о которых сообщилиmlogit?
Я хотел бы сообщить о своих результатахLatex использование файлаstargazer, При этом возникает проблемный компромисс:
Если я использую результаты изmlogit затем я получаю желаемую статистику, такую как psuedo R в квадрате, однако вывод выводится в длинном формате (см. пример ниже).
Если я использую результаты изnnet тогда формат будет таким, как ожидалось, но он сообщает статистику, которая мне не интересна, например, AIC, но не включает, например, psuedo R в квадрате.
Я хотел бы получить статистикуmlogit в форматированииnnet когда я используюstargazer.
Вот воспроизводимый пример с тремя вариантами выбора:
library(mlogit)
df = data.frame(c(0,1,1,2,0,1,0), c(1,6,7,4,2,2,1), c(683,276,756,487,776,100,982))
colnames(df) <- c('y', 'col1', 'col2')
mydata = df
mldata <- mlogit.data(mydata, choice="y", shape="wide")
mlogit.model1 <- mlogit(y ~ 1| col1+col2, data=mldata)
Вывод tex при компиляции имеет то, что я называю «длинным форматом», который я считаю нежелательным:

Теперь, используяnnet:
library(nnet)
mlogit.model2 = multinom(y ~ 1 + col1+col2, data=mydata)
stargazer(mlogit.model2)
Дает вывод tex:
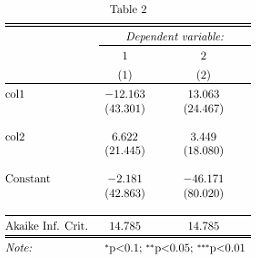
который имеет "широкий" формат, который я желаю. Обратите внимание на разные коэффициенты и стандартные ошибки.