Спасибо за ответ, @Darth_vader. Я понимаю, что это можно сделать с помощью logstash, но я использую fluentd для сбора журналов, см. Конфигурацию в моем вопросе. Знаете ли вы, как это можно сделать с беглым из коробки?
я есть своего рода стек ELK, с fluentd вместо logstash, работающий как DaemonSet в кластере Kubernetes и отправляющий все журналы из всех контейнеров в формате logstash на сервер Elasticsearch.
Из множества контейнеров, запущенных в кластере Kubernetes, некоторые являются контейнерами nginx, которые выводят журналы следующего формата:
121.29.251.188 - [16/Feb/2017:09:31:35 +0000] host="subdomain.site.com" req="GET /data/schedule/update?date=2017-03-01&type=monthly&blocked=0 HTTP/1.1" status=200 body_bytes=4433 referer="https://subdomain.site.com/schedule/2589959/edit?location=23092&return=monthly" user_agent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0" time=0.130 hostname=webapp-3188232752-ly36o
Поля, видимые в Кибане, как на этом скриншоте:
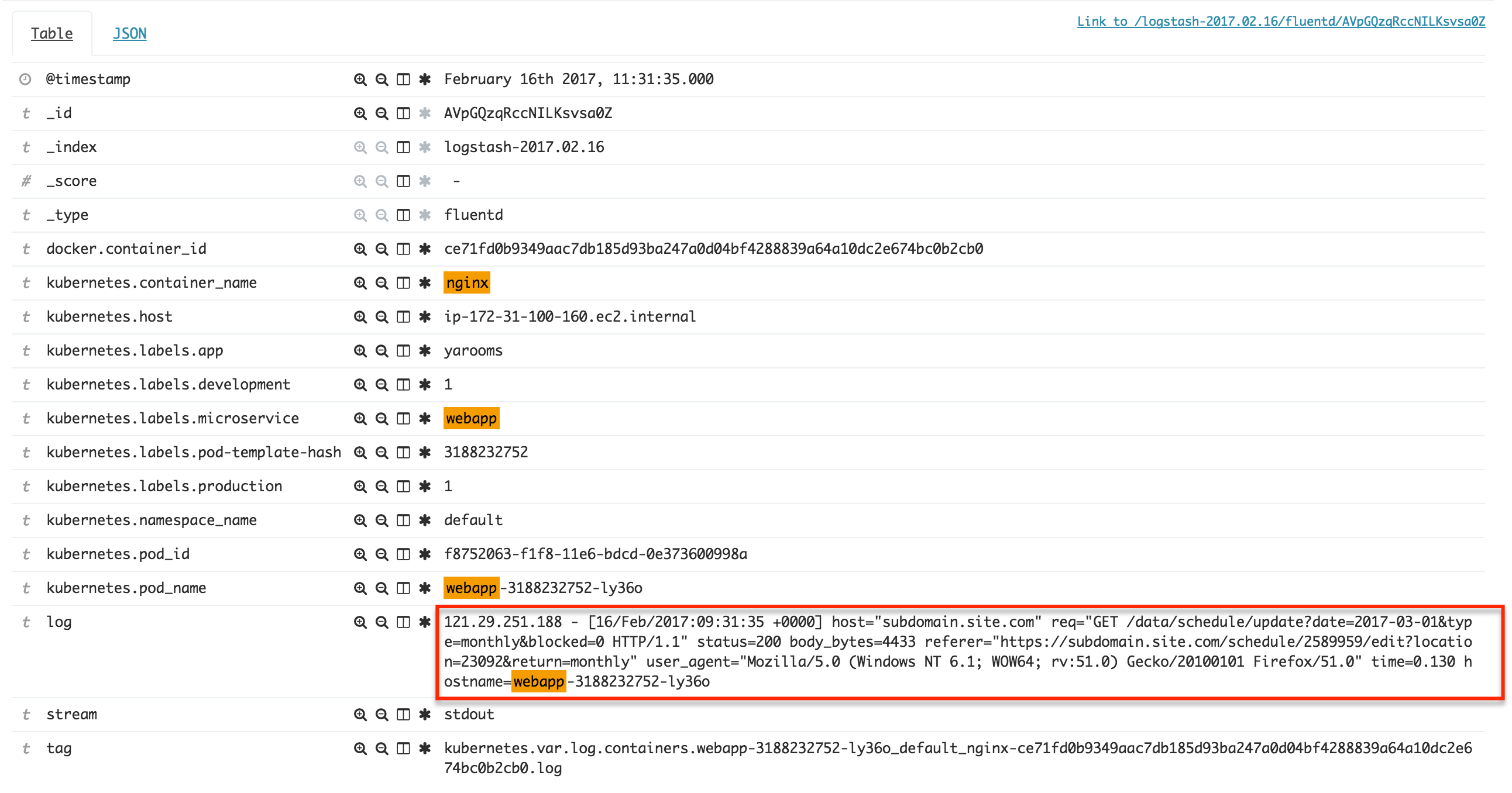
Можно ли извлечь поля из этого типа журнала после его индексации?
Коллектор fluentd сконфигурирован со следующим источником, который обрабатывает все контейнеры, поэтому применение формата на этом этапе невозможно из-за очень разных выходных данных из разных контейнеров:
<source>
type tail
path /var/log/containers/*.log
pos_file /var/log/es-containers.log.pos
time_format %Y-%m-%dT%H:%M:%S.%NZ
tag kubernetes.*
format json
read_from_head true
</source>
В идеальной ситуации я хотел бы дополнить поля, видимые на скриншоте выше, мета-полями в поле «log», такими как «host», «req», «status» и т. Д.