GLSL SpinLock только в основном работает
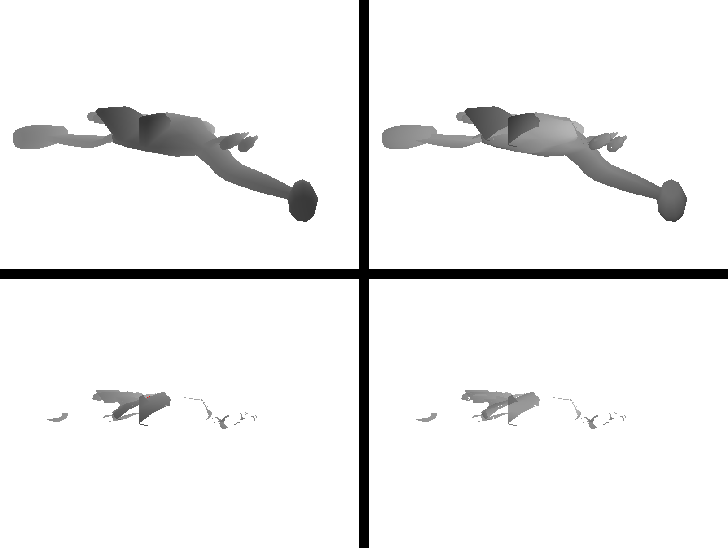
Я реализовал алгоритм глубинного пилинга, используя спинлок GLSL (вдохновленныйэтот). В следующей визуализации обратите внимание на то, как в целом работает алгоритм отслаивания по глубине (первый слой вверху слева, второй слой вверху справа, третий слой внизу слева, четвертый слой внизу справа). Четыре слоя глубины хранятся в одной текстуре RGBA.
К сожалению, спин-блокировка иногда не может предотвратить ошибки - вы можете увидеть маленькие белые пятнышки, особенно в четвертом слое. Также имеется один на крыле космического корабля во втором слое. Эти спеклы меняются в каждом кадре.
В моем GLSL-спин-блокировке, когда фрагмент должен быть нарисован, программа-фрагмент считывает и записывает значение блокировки в отдельную текстуру блокировки атомарно, ожидая, пока не появится 0, указывая, что блокировка открыта.На практикеЯ обнаружил, что программа должна быть параллельной, потому что, если два потока находятся на одном пикселе, деформация не может продолжаться (один должен ждать, пока другой продолжается, и все потоки в деформации потока GPU должны выполняться одновременно).
Моя фрагментная программа выглядит так (комментарии и интервалы добавлены):
#version 420 core
//locking texture
layout(r32ui) coherent uniform uimage2D img2D_0;
//data texture, also render target
layout(RGBA32F) coherent uniform image2D img2D_1;
//Inserts "new_data" into "data", a sorted list
vec4 insert(vec4 data, float new_data) {
if (new_data<data.x) return vec4( new_data,data.xyz);
else if (new_data<data.y) return vec4(data.x,new_data,data.yz);
else if (new_data<data.z) return vec4(data.xy,new_data,data.z);
else if (new_data<data.w) return vec4(data.xyz,new_data );
else return data;
}
void main() {
ivec2 coord = ivec2(gl_FragCoord.xy);
//The idea here is to keep looping over a pixel until a value is written.
//By looping over the entire logic, threads in the same warp aren't stalled
//by other waiting threads. The first imageAtomicExchange call sets the
//locking value to 1. If the locking value was already 1, then someone
//else has the lock, and can_write is false. If the locking value was 0,
//then the lock is free, and can_write is true. The depth is then read,
//the new value inserted, but only written if can_write is true (the
//locking texture was free). The second imageAtomicExchange call resets
//the lock back to 0.
bool have_written = false;
while (!have_written) {
bool can_write = (imageAtomicExchange(img2D_0,coord,1u) != 1u);
memoryBarrier();
vec4 depths = imageLoad(img2D_1,coord);
depths = insert(depths,gl_FragCoord.z);
if (can_write) {
imageStore(img2D_1,coord,depths);
have_written = true;
}
memoryBarrier();
imageAtomicExchange(img2D_0,coord,0);
memoryBarrier();
}
discard; //Already wrote to render target with imageStore
}
Мой вопрос: почему происходит такое пятнистое поведение? Я хочу чтобы спинлок работал 100% времени! Может ли это быть связано с моим размещением memoryBarrier ()?