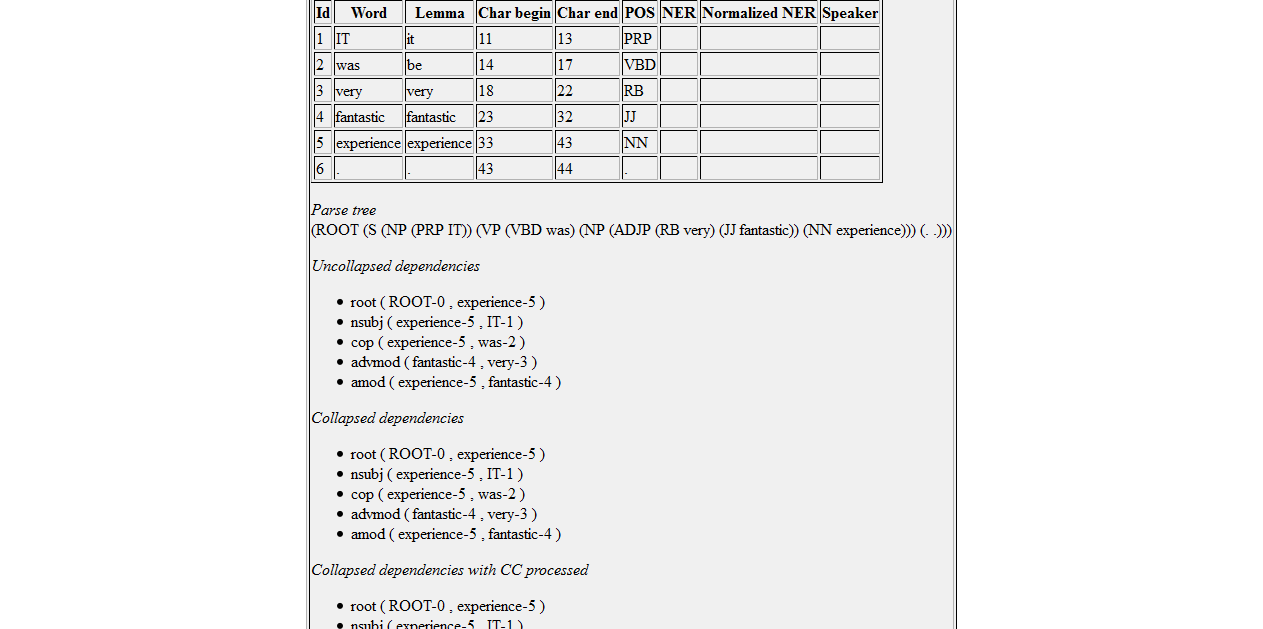
Выполнение и тестирование примера stanford core nlp
Я скачал пакеты nlp для ядра stanford и попытался протестировать его на своей машине.
Используя команду:java -cp "*" -mx1g edu.stanford.nlp.sentiment.SentimentPipeline -file input.txt
Я получил результат настроения в видеpositive или же .negativeinput.txt содержит предложение для тестирования.
По большей команде:java -cp stanford-corenlp-3.3.0.jar;stanford-corenlp-3.3.0-models.jar;xom.jar;joda-time.jar -Xmx600m edu.stanford.nlp.pipeline.StanfordCoreNLP -annotators tokenize,ssplit,pos,lemma,parse -file input.txt при исполнении дает следующие строки:
H:\Drive E\Stanford\stanfor-corenlp-full-2013~>java -cp stanford-corenlp-3.3.0.j
ar;stanford-corenlp-3.3.0-models.jar;xom.jar;joda-time.jar -Xmx600m edu.stanford
.nlp.pipeline.StanfordCoreNLP -annotators tokenize,ssplit,pos,lemma,parse -file
input.txt
Adding annotator tokenize
Adding annotator ssplit
Adding annotator pos
Reading POS tagger model from edu/stanford/nlp/models/pos-tagger/english-left3wo
rds/english-left3words-distsim.tagger ... done [36.6 sec].
Adding annotator lemma
Adding annotator parse
Loading parser from serialized file edu/stanford/nlp/models/lexparser/englishPCF
G.ser.gz ... done [13.7 sec].
Ready to process: 1 files, skipped 0, total 1
Processing file H:\Drive E\Stanford\stanfor-corenlp-full-2013~\input.txt ... wri
ting to H:\Drive E\Stanford\stanfor-corenlp-full-2013~\input.txt.xml {
Annotating file H:\Drive E\Stanford\stanfor-corenlp-full-2013~\input.txt [13.6
81 seconds]
} [20.280 seconds]
Processed 1 documents
Skipped 0 documents, error annotating 0 documents
Annotation pipeline timing information:
PTBTokenizerAnnotator: 0.4 sec.
WordsToSentencesAnnotator: 0.0 sec.
POSTaggerAnnotator: 1.8 sec.
MorphaAnnotator: 2.2 sec.
ParserAnnotator: 9.1 sec.
TOTAL: 13.6 sec. for 10 tokens at 0.7 tokens/sec.
Pipeline setup: 58.2 sec.
Total time for StanfordCoreNLP pipeline: 79.6 sec.
H:\Drive E\Stanford\stanfor-corenlp-full-2013~>
Мог понять. Нет информативного результата.
Я получил один пример на:Ядро Стэнфорда
import java.io.*;
import java.util.*;
import edu.stanford.nlp.io.*;
import edu.stanford.nlp.ling.*;
import edu.stanford.nlp.pipeline.*;
import edu.stanford.nlp.trees.*;
import edu.stanford.nlp.util.*;
public class StanfordCoreNlpDemo {
public static void main(String[] args) throws IOException {
PrintWriter out;
if (args.length > 1) {
out = new PrintWriter(args[1]);
} else {
out = new PrintWriter(System.out);
}
PrintWriter xmlOut = null;
if (args.length > 2) {
xmlOut = new PrintWriter(args[2]);
}
StanfordCoreNLP pipeline = new StanfordCoreNLP();
Annotation annotation;
if (args.length > 0) {
annotation = new Annotation(IOUtils.slurpFileNoExceptions(args[0]));
} else {
annotation = new Annotation("Kosgi Santosh sent an email to Stanford University. He didn't get a reply.");
}
pipeline.annotate(annotation);
pipeline.prettyPrint(annotation, out);
if (xmlOut != null) {
pipeline.xmlPrint(annotation, xmlOut);
}
// An Annotation is a Map and you can get and use the various analyses individually.
// For instance, this gets the parse tree of the first sentence in the text.
List sentences = annotation.get(CoreAnnotations.SentencesAnnotation.class);
if (sentences != null && sentences.size() > 0) {
CoreMap sentence = sentences.get(0);
Tree tree = sentence.get(TreeCoreAnnotations.TreeAnnotation.class);
out.println();
out.println("The first sentence parsed is:");
tree.pennPrint(out);
}
}
}
Пытался выполнить это в netbeans с включением необходимой библиотеки. Но он всегда застревает или дает исключениеException in thread “main” java.lang.OutOfMemoryError: Java heap space
Ты установил память, которая будет выделена вproperty/run/VM box
Любая идея, как я могу запустить выше Java-пример с помощью командной строки?
Я хочу получить оценку настроения примера
ОБНОВИТЬ
вывод:java -cp "*" -mx1g edu.stanford.nlp.sentiment.SentimentPipeline -file input.txt
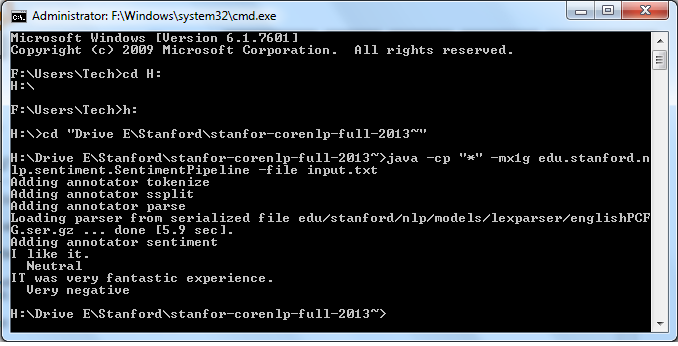
выход из:java -cp stanford-corenlp-3.3.0.j ar;stanford-corenlp-3.3.0-models.jar;xom.jar;joda-time.jar -Xmx600m edu.stanford .nlp.pipeline.StanfordCoreNLP -annotators tokenize,ssplit,pos,lemma,parse -file input.txt