Алгоритмы кластеризации Python
я искал scipy и sklearn для алгоритмов кластеризации для конкретной проблемы, которая у меня есть. Мне нужен какой-то способ охарактеризовать популяцию N частиц в k групп, где k не обязательно знать, и в дополнение к этому не известны априорные длины связывания (аналогично этомувопрос).Я'
я пробовал kmeans, который хорошо работает, если вызнать сколько кластеров вы хотите. Я'я пробовал dbscan, который плохо работает, если высказать это характерная шкала длины, на которой перестать искать (или начинать искать) кластеры. Проблема в том, что у меня есть потенциально тысячи таких скоплений частиц, и я не могу тратить время на то, чтобы рассказать алгоритмам kmeans / dbscan, с чего они должны исходить.
Вот пример того, что dbscan может найти: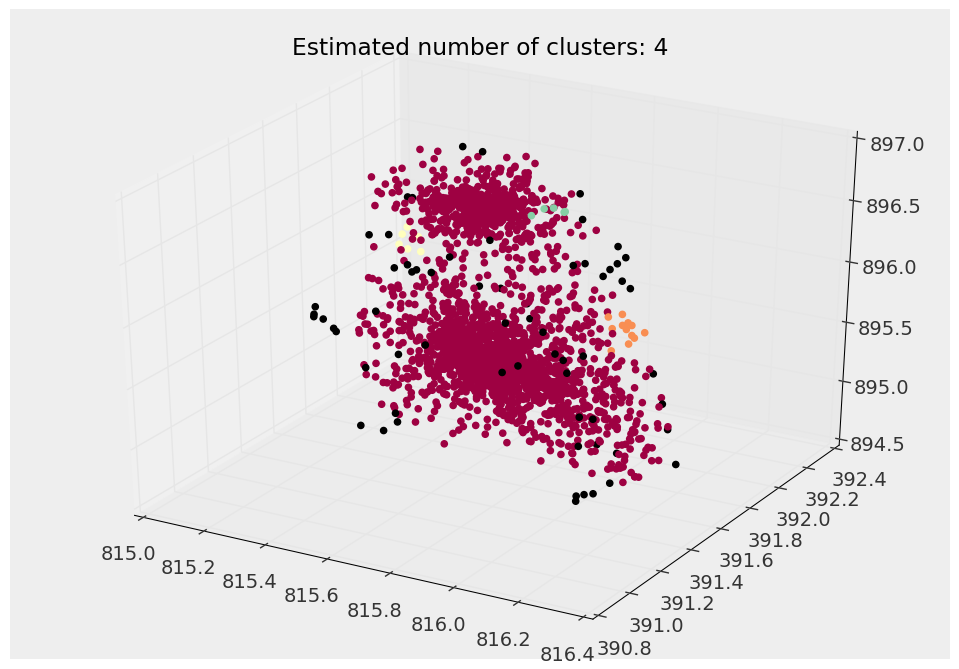
Вы можете видеть, что на самом деле здесь есть две отдельные популяции, хотя, регулируя фактор эпсилона (параметр макс. Расстояние между соседними кластерами), я просто не могу заставить его видеть эти две популяции частиц.
Есть ли другие алгоритмы, которые будут работать здесь? Я'ищу минимальную информацию заранее - другими словами, яМне нравится алгоритм, чтобы быть в состоянии сделать "умный" решения о том, что может составлять отдельный кластер.