Android - оверлейный макет позволяет прикасаться через LinearLayout
в следующем пользовательском интерфейсе у меня есть это перетаскиваемое наложение на весь экран. LinearLayout прозрачен и позволяет элементам управления под ним быть кликабельными или сенсорными. По сути, я могу прокрутить список ниже этой LinearLayout, а также щелкнуть элементы управления. Как мне это отключить?
Смотрите прикрепленный пример.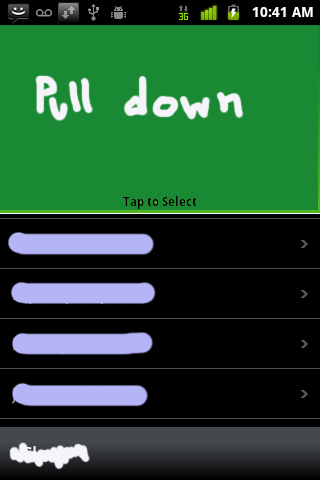
Спасибо
<code><RelativeLayout
xmlns:android="http://schemas.android.com/apk/res/android"
android:id="@+id/rlExtNavbar"
android:orientation="vertical"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:gravity="fill_vertical"
android:layout_gravity="fill_vertical"
android:background="@color/transparent" xmlns:tools="http://schemas.android.com/tools" tools:ignore="Overdraw">
<RelativeLayout
android:id="@+id/expandedNavbarLayout"
android:orientation="vertical"
android:layout_width="fill_parent"
android:layout_height="wrap_content" >
</RelativeLayout>
<LinearLayout
android:id="@+id/transparentLayout"
android:orientation="vertical"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:layout_below="@id/expandedNavbarLayout"
android:focusableInTouchMode="false"
android:focusable="false"
android:background="@color/fulltransparent">
</LinearLayout>
</RelativeLayout>
</code>