O desempenho do multiprocessamento Python melhora apenas com a raiz quadrada do número de núcleos usados
Estou tentando implementar o multiprocessamento em Python (Windows Server 2012) e estou tendo problemas para alcançar o grau de melhoria de desempenho que eu espero. Em particular, para um conjunto de tarefas quase inteiramente independentes,Eu esperaria uma melhoria linear com núcleos adicionais.
Entendo que - especialmente no Windows - há uma sobrecarga envolvida na abertura de novos processos[1], e que muitas peculiaridades do código subjacente podem atrapalhar uma tendência limpa. Mas, em teoria, a tendência ainda deve estar próxima de linear para uma tarefa totalmente paralela.[2]; ou talvez logística, se eu estivesse lidando com uma tarefa parcialmente serial[3].
No entanto, quando executo o multiprocessamento.Pool em uma função de teste de verificação primária (código abaixo), obtenho um relacionamento de raiz quadrada quase perfeito atéN_cores=36 (o número de núcleos físicos no meu servidor) antes que o desempenho esperado seja atingido quando eu entrar nos núcleos lógicos adicionais.
Aqui é uma plotagem dos meus resultados dos testes de desempenho:
("Desempenho Normalizado" é[ um tempo de execução com1 CPU-core] dividido por[ um tempo de execução comN Núcleos de CPU] )
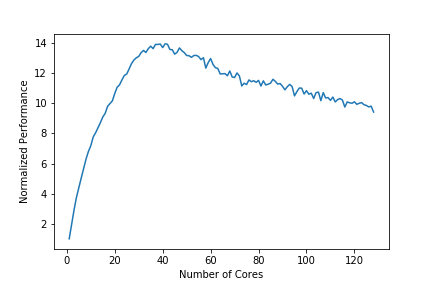
{kind=link}
É normal ter essa diminuição dramática de retornos com o multiprocessamento? Ou estou perdendo algo com minha implementação?
import numpy as np
from multiprocessing import Pool, cpu_count, Manager
import math as m
from functools import partial
from time import time
def check_prime(num):
#Assert positive integer value
if num!=m.floor(num) or num<1:
print("Input must be a positive integer")
return None
#Check divisibility for all possible factors
prime = True
for i in range(2,num):
if num%i==0: prime=False
return prime
def cp_worker(num, L):
prime = check_prime(num)
L.append((num, prime))
def mp_primes(omag, mp=cpu_count()):
with Manager() as manager:
np.random.seed(0)
numlist = np.random.randint(10**omag, 10**(omag+1), 100)
L = manager.list()
cp_worker_ptl = partial(cp_worker, L=L)
try:
pool = Pool(processes=mp)
list(pool.imap(cp_worker_ptl, numlist))
except Exception as e:
print(e)
finally:
pool.close() # no more tasks
pool.join()
return L
if __name__ == '__main__':
rt = []
for i in range(cpu_count()):
t0 = time()
mp_result = mp_primes(6, mp=i+1)
t1 = time()
rt.append(t1-t0)
print("Using %i core(s), run time is %.2fs" % (i+1, rt[-1]))
Nota: Estou ciente de que, para esta tarefa, seria provavelmente mais eficiente implementar váriosrosqueamento, mas o script real para o qual este é um analógico simplificado é incompatível com o multithreading do Python devido ao GIL.