Maneira eficiente de plotar dados em uma grade irregular
Trabalho com dados de satélite organizados em uma grade bidimensional irregular, cujas dimensões são a linha de varredura (ao longo da dimensão da trilha) e o pixel do solo (na dimensão da trilha). As informações de latitude e longitude para cada pixel central são armazenadas em variáveis de coordenadas auxiliares, bem como nos pares de coordenadas dos quatro cantos (as coordenadas de latitude e longitude são fornecidas no elipsóide de referência WGS84). Os dados são armazenados em arquivos netCDF4.
O que estou tentando fazer é plotar esses arquivos com eficiência (e possivelmente uma combinação de arquivos - próximo passo!) Em um mapa projetado.
Minha abordagem até agora, inspirada emJeremy Voisey's responda a issoPergunta, questão, foi criar um quadro de dados que vincule minha variável de interesse aos limites de pixel e usarggplot2 comgeom_polygon para o enredo real.
Deixe-me ilustrar meu fluxo de trabalho e peço desculpas antecipadamente pela abordagem ingênua: eu apenas comecei a codificar com R há uma ou duas semanas.
Nota
Para reproduzir completamente o problema:
1. baixe os dois quadros de dados:so2df.Rda (22 milhões) epixel_corners.Rda (26 milhões)
2. carregue-os em seu ambiente, por exemplo
so2df <- readRDS(file="so2df.Rda")
pixel_corners <- readRDS(file="pixel_corners.Rda")
Vou ler os dados e os limites de latitude / longitude do meu arquivo.
library(ncdf4)
library(ggplot2)
library(ggmap)
# set path and filename
ncpath <- "/Users/stefano/src/s5p/products/e1dataset/L2__SO2/"
ncname <- "S5P_OFFL_L2__SO2____20171128T234133_20171129T003956_00661_01_022943_00000000T000000"
ncfname <- paste(ncpath, ncname, ".nc", sep="")
nc <- nc_open(ncfname)
# save fill value and multiplication factors
mfactor = ncatt_get(nc, "PRODUCT/sulfurdioxide_total_vertical_column",
"multiplication_factor_to_convert_to_DU")
fillvalue = ncatt_get(nc, "PRODUCT/sulfurdioxide_total_vertical_column",
"_FillValue")
# read the SO2 total column variable
so2tc <- ncvar_get(nc, "PRODUCT/sulfurdioxide_total_vertical_column")
# read lat/lon of centre pixels
lat <- ncvar_get(nc, "PRODUCT/latitude")
lon <- ncvar_get(nc, "PRODUCT/longitude")
# read latitude and longitude bounds
lat_bounds <- ncvar_get(nc, "GEOLOCATIONS/latitude_bounds")
lon_bounds <- ncvar_get(nc, "GEOLOCATIONS/longitude_bounds")
# close the file
nc_close(nc)
dim(so2tc)
## [1] 450 3244
Portanto, para este arquivo / passe, existem 450 pixels no solo para cada uma das 3244 linhas de verificação.
Crie os quadros de dadosAqui, crio dois quadros de dados, um para os valores, com algum pós-processamento, e outro para os limites de latitude / longitude, depois mesclo os dois quadros de dados.
so2df <- data.frame(lat=as.vector(lat), lon=as.vector(lon), so2tc=as.vector(so2tc))
# add id for each pixel
so2df$id <- row.names(so2df)
# convert to DU
so2df$so2tc <- so2df$so2tc*as.numeric(mfactor$value)
# replace fill values with NA
so2df$so2tc[so2df$so2tc == fillvalue] <- NA
saveRDS(so2df, file="so2df.Rda")
summary(so2df)
## lat lon so2tc id
## Min. :-89.97 Min. :-180.00 Min. :-821.33 Length:1459800
## 1st Qu.:-62.29 1st Qu.:-163.30 1st Qu.: -0.48 Class :character
## Median :-19.86 Median :-150.46 Median : -0.08 Mode :character
## Mean :-13.87 Mean : -90.72 Mean : -1.43
## 3rd Qu.: 31.26 3rd Qu.: -27.06 3rd Qu.: 0.26
## Max. : 83.37 Max. : 180.00 Max. :3015.55
## NA's :200864
Salvei esse quadro de dados comoso2df.Rda aqui (22 milhões).
num_points = dim(lat_bounds)[1]
pixel_corners <- data.frame(lat_bounds=as.vector(lat_bounds), lon_bounds=as.vector(lon_bounds))
# create id column by replicating pixel's id for each of the 4 corner points
pixel_corners$id <- rep(so2df$id, each=num_points)
saveRDS(pixel_corners, file="pixel_corners.Rda")
summary(pixel_corners)
## lat_bounds lon_bounds id
## Min. :-89.96 Min. :-180.00 Length:5839200
## 1st Qu.:-62.29 1st Qu.:-163.30 Class :character
## Median :-19.86 Median :-150.46 Mode :character
## Mean :-13.87 Mean : -90.72
## 3rd Qu.: 31.26 3rd Qu.: -27.06
## Max. : 83.40 Max. : 180.00
Como esperado, o quadro de dados dos limites de lat / lon é quatro vezes maior que o valor do quadro de dados (quatro pontos para cada pixel / valor).
Salvei esse quadro de dados comopixel_corners.Rda aqui (26 milhões).
Em seguida, mesclo os dois quadros de dados por ID:
start_time <- Sys.time()
so2df <- merge(pixel_corners, so2df, by=c("id"))
time_taken <- Sys.time() - start_time
print(paste(dim(so2df)[1], "rows merged in", time_taken, "seconds"))
## [1] "5839200 rows merged in 42.4763631820679 seconds"
Como você pode ver, é um processo intensivo de CPU. Eu me pergunto o que aconteceria se eu trabalhasse com 15 arquivos de uma vez (cobertura global).
Plotando os dadosAgora que tenho os cantos dos meus pixels vinculados ao valor do pixel, posso plotá-los facilmente. Normalmente, estou interessado em uma região específica da órbita, então criei uma função que subconecta o dataframe de entrada antes de plotá-lo:
PlotRegion <- function(so2df, latlon, title) {
# Plot the given dataset over a geographic region.
#
# Args:
# df: The dataset, should include the no2tc, lat, lon columns
# latlon: A vector of four values identifying the botton-left and top-right corners
# c(latmin, latmax, lonmin, lonmax)
# title: The plot title
# subset the data frame first
df_sub <- subset(so2df, lat>latlon[1] & lat<latlon[2] & lon>latlon[3] & lon<latlon[4])
subtitle = paste("#Pixel =", dim(df_sub)[1], "- Data min =",
formatC(min(df_sub$so2tc, na.rm=T), format="e", digits=2), "max =",
formatC(max(df_sub$so2tc, na.rm=T), format="e", digits=2))
ggplot(df_sub) +
geom_polygon(aes(y=lat_bounds, x=lon_bounds, fill=so2tc, group=id), alpha=0.8) +
borders('world', xlim=range(df_sub$lon), ylim=range(df_sub$lat),
colour='gray20', size=.2) +
theme_light() +
theme(panel.ontop=TRUE, panel.background=element_blank()) +
scale_fill_distiller(palette='Spectral') +
coord_quickmap(xlim=c(latlon[3], latlon[4]), ylim=c(latlon[1], latlon[2])) +
labs(title=title, subtitle=subtitle,
x="Longitude", y="Latitude",
fill=expression(DU))
}
Em seguida, invoco minha função em uma região de interesse, por exemplo, vamos ver o que acontece no Havaí:
latlon = c(17.5, 22.5, -160, -154)
PlotRegion(so2df, latlon, expression(SO[2]~total~vertical~column))
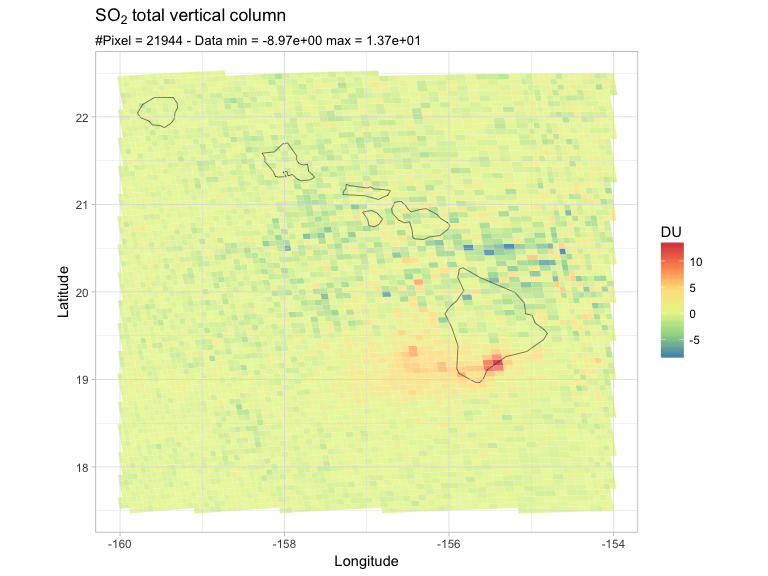
Lá estão eles, meus pixels, e o que parece ser uma pluma de SO2 do Mauna Loa. Por favor, ignore os valores negativos por enquanto. Como você pode ver, a área dos pixels varia em direção à borda da faixa (esquema de binning diferente).
Tentei mostrar o mesmo gráfico nos mapas do google, usando o ggmap:
PlotRegionMap <- function(so2df, latlon, title) {
# Plot the given dataset over a geographic region.
#
# Args:
# df: The dataset, should include the no2tc, lat, lon columns
# latlon: A vector of four values identifying the botton-left and top-right corners
# c(latmin, latmax, lonmin, lonmax)
# title: The plot title
# subset the data frame first
df_sub <- subset(so2df, lat>latlon[1] & lat<latlon[2] & lon>latlon[3] & lon<latlon[4])
subtitle = paste("#Pixel =", dim(df_sub)[1], "Data min =", formatC(min(df_sub$so2tc, na.rm=T), format="e", digits=2),
"max =", formatC(max(df_sub$so2tc, na.rm=T), format="e", digits=2))
base_map <- get_map(location = c(lon = (latlon[4]+latlon[3])/2, lat = (latlon[1]+latlon[2])/2), zoom = 7, maptype="terrain", color="bw")
ggmap(base_map, extent = "normal") +
geom_polygon(data=df_sub, aes(y=lat_bounds, x=lon_bounds,fill=so2tc, group=id), alpha=0.5) +
theme_light() +
theme(panel.ontop=TRUE, panel.background=element_blank()) +
scale_fill_distiller(palette='Spectral') +
coord_quickmap(xlim=c(latlon[3], latlon[4]), ylim=c(latlon[1], latlon[2])) +
labs(title=title, subtitle=subtitle,
x="Longitude", y="Latitude",
fill=expression(DU))
}
E é isso que eu recebo:
latlon = c(17.5, 22.5, -160, -154)
PlotRegionMap(so2df, latlon, expression(SO[2]~total~vertical~column))

sf pacote, e eu queria saber se eu poderia definir um quadro de dados de pontos (valores + coordenadas de pixel central) e tersf inferir automaticamente os limites de pixel. Isso me pouparia de ter que confiar nos limites de lat / lon definidos no meu conjunto de dados original e ter que mesclá-los com meus valores. Eu poderia aceitar uma perda de precisão nas áreas de transição em direção à borda da faixa, caso contrário, a grade é bastante regular, cada pixel sendo 3,5x7 km ^ 2 grande.Reorganizar meus dados em uma grade regular (como?), Possivelmente agregando pixels adjacentes, melhoraria o desempenho? Eu estava pensando em usar oraster pacote, que, como eu entendi, requer dados em uma grade regular. Isso deve ser útil em escala global (por exemplo, plotagens na Europa), onde eu não preciso plotar os pixels individuais - na verdade, eu nem conseguia vê-los.Preciso reprojetar meus dados ao traçar sobre o google map?[perguntas cosméticas bônus]
Existe uma maneira mais elegante de agrupar meu quadro de dados em uma região identificada por seus quatro pontos de canto?Como alterar a escala de cores para destacar os valores mais altos em relação aos valores mais baixos? Eu experimentei com escala de log com resultados ruins.