Como obter o nó raiz na árvore Stanford Parse?
Eu tenho essa árvore de análise aqui:
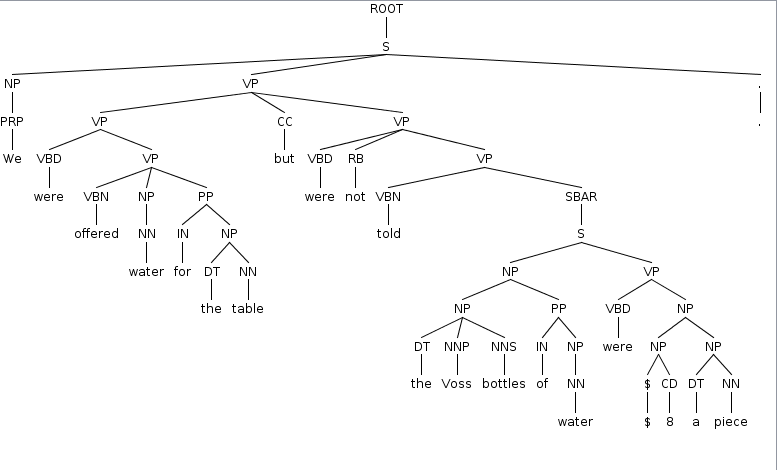
O que eu quero é obter todas as palavras de um pai comum, dadas uma palavra no conjunto de filhos de uma subárvore. Por exemplo, se você pegar a palavra "garrafas"então eu quero pegar"as garrafas Voss"ou talvez até"as garrafas de água Voss"mas eu não sei como fazer isso.
Annotation document = new Annotation(sentenceText);
this.pipeline.annotate(document);
List<CoreMap> sentences = document.get(SentencesAnnotation.class);
for (CoreMap sentence : sentences) {
Tree tree = sentence.get(TreeAnnotation.class);
List<Tree> leaves = new ArrayList<>();
leaves = tree.getLeaves(leaves);
for (Tree leave : leaves) {
String compare = leave.toString().toLowerCase();
if(compare.equals(word) == true) {
// Get other nodes in the same subtree
}
}
}
Chamandoleave.parent() não funciona. Eu também tenteitree.parent(leave) mas isso também não funciona (retornanull)
Eu também tentei
for (Tree leave : tree) {
String compare = leave.toString().toLowerCase();
if(compare.equals(word) == true) {
// ..
}
}
mas eu entendo o mesmo.
public Tree parent(Tree root)
Retorne o pai do nó da árvore. Essa rotina percorrerá uma árvore (profundidade primeiro) a partir da raiz especificada e encontrará o pai corretamente, independentemente de a classe concreta armazenar os pais. Ele retornará nulo apenas se este nó for o nó raiz ou se este nó não estiver contido na árvore enraizada na raiz.
Como posso fazer isso?#EverythingIsBrokenAllTheTime