Que tipo de classificação é essa?
Digamos que eu tenha uma lista de inteiros, onde cada elemento é um número de 1 a 20. (Não é isso que estou tentando classificar).
Agora, eu tenho uma matriz de "operações", onde cada operação:
Remove certos números (conhecidos) da listae Adiciona certos outros números (conhecidos) à listae Não é possível manipular a lista se ela contiver certos números (conhecidos) no início da operação - chame-osEvitaEdit: Pode haver zero ou mais números em cada um dosAdiciona, RemoveeEvita para cada operação, e cada número pode aparecer zero ou mais vezes em cada grupo para alguma operação. Para qualquer operação,Adiciona eRemove são disjuntos,Evita eRemove são disjuntos, masAdiciona eEvita pode se sobrepor.
Eu quero classificar a matriz de operações para que, para cada operação:
Se a operaçãoEvita itens, é colocado após uma operação queRemove esses números. Se não imediatamente depois, não pode haverAdiciona operação que adiciona esses números de volta entre o últimoRemove e aEvita.Se a operaçãoRemove itens, todas as operações queAdiciona qualquer um desses itens é colocado antes dele.No caso de uma dependência circular, a cadeia de operações deve remover tantos números quanto possívele informe-me que não foi possível remover todos os números.
Existe um nome / implementação para este tipo de algoritmo que supera o que eu tenho abaixo?
Adicionado 8/23: A recompensa é para cobrir os requisitos de classificação, considerando ambos os OpCodes (conjunto de estruturas) eInstructionSemantics (conjunto de sinalizadores de bit de uma enumeração).
Adicionado depois 8/23: Fiz uma melhoria de desempenho de 89: 1, classificando heuristicamente a matriz de origem. Veja minha resposta atual para detalhes.
namespace Pimp.Vmx.Compiler.Transforms
{
using System;
using System.Collections.Generic;
using System.Reflection.Emit;
internal interface ITransform
{
IEnumerable<OpCode> RemovedOpCodes { get; }
IEnumerable<OpCode> InsertedOpCodes { get; }
IEnumerable<OpCode> PreventOpCodes { get; }
InstructionSemantics RemovedSemantics { get; }
InstructionSemantics InsertedSemantics { get; }
InstructionSemantics PreventSemantics { get; }
}
[Flags]
internal enum InstructionSemantics
{
None,
ReadBarrier = 1 << 0,
WriteBarrier = 1 << 1,
BoundsCheck = 1 << 2,
NullCheck = 1 << 3,
DivideByZeroCheck = 1 << 4,
AlignmentCheck = 1 << 5,
ArrayElementTypeCheck = 1 << 6,
}
internal class ExampleUtilityClass
{
public static ITransform[] SortTransforms(ITransform[] transforms)
{
throw new MissingMethodException("Gotta do something about this...");
}
}
}
Eu tenho um sistema que lê em uma lista de itens e envia para outro "módulo" para processamento. Cada item é uma instrução na minha representação intermediária em um compilador - basicamente um número de 1 a ~ 300 mais alguma combinação de cerca de 17 modificadores disponíveis (enumeração de sinalizadores). A complexidade do sistema de processamento (montador de código de máquina) é proporcional ao número de possíveis entradas únicas (número + flags), onde eu tenho que codificar manualmente cada manipulador único. Além disso, tenho que escrever pelo menos três sistemas de processamento independentes (X86, X64, ARM) - a quantidade de código de processamento real que posso usar para vários sistemas de processamento é mínima.
Ao inserir "operações" entre leitura e processamento, posso garantir que determinados itens nunca apareçam para processamento - faço isso expressando os números e / ou sinalizadores em termos de outros números. Eu posso codificar cada "operação de transformação" em uma caixa preta descrevendo seus efeitos, o que me poupa uma tonelada de complexidade por operação. As operações são complexas e exclusivas para cada transformação, mas muito mais fáceis do que o sistema de processamento. Para mostrar quanto tempo isso economiza, uma das minhas operações remove completamente 6 das bandeiras, escrevendo os efeitos desejados em termos de cerca de 6 números (sem sinalizadores).
Para manter as coisas na caixa preta, eu quero um algoritmo de ordenação para tomar todas as operações que escrevo, para que tenham o maior impacto e me informar sobre o sucesso que tive em simplificar os dados que eventualmente atingirão o sistema de processamento. (s) Naturalmente, estou direcionando os itens mais complexos na representação intermediária e simplificando-os para a aritmética básica de ponteiros, sempre que possível, o que é mais fácil de manipular nos montadores. :)
Com tudo isso dito, adicionarei outra nota. Os efeitos da operação são descritos como "efeitos de atributo" na lista de instruções. Em geral, as operações se comportam bem, mas algumas delas apenas removem números que caem depois de outros números (como remover todos os 6 que não seguem um 16). Outros removem todas as instâncias de um determinado número que contém determinados sinalizadores. Eu cuidarei disso mais tarde - depois que eu descobrir o problema básico de adicionar / remover / prevenir garantido listado acima.
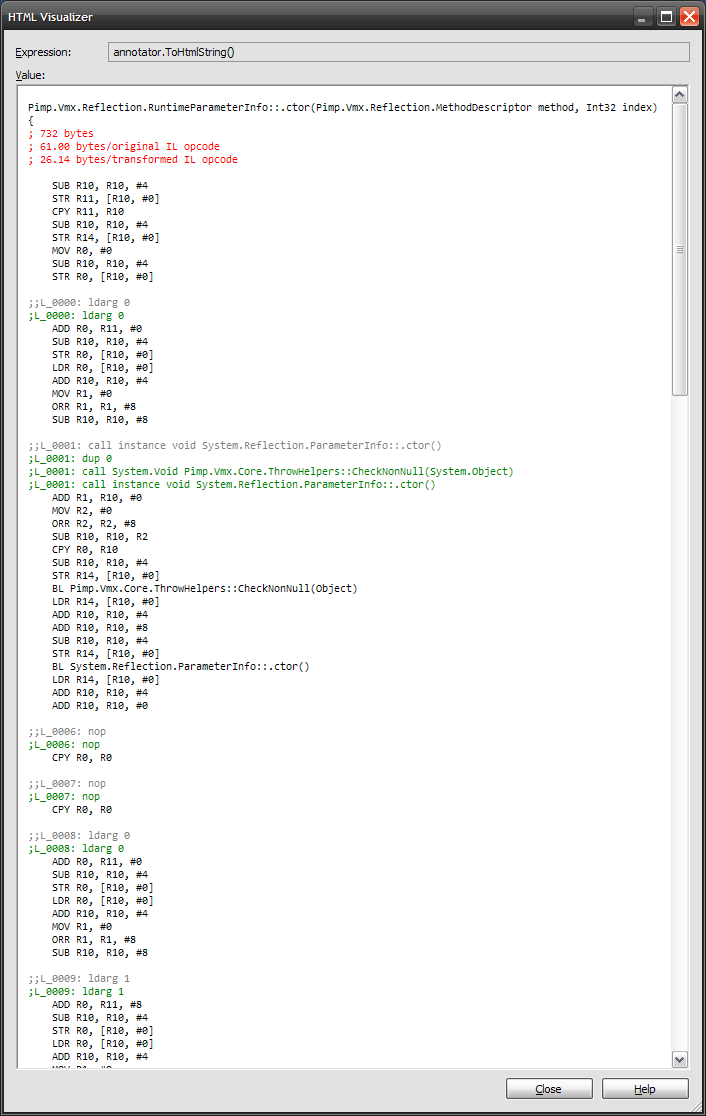
Adicionado 8/23: Nesta imagem, você pode ver umcall instrução (cinza) que tinhaInstructionSemantics.NullCheck foi processado peloRemoveNullReferenceChecks transformar para remover o sinalizador de semântica em troca de adicionar outra chamada (sem semântica anexada à chamada adicionada). Agora o montador não precisa entender / manipularInstructionSemantics.NullCheckporque nunca os verá. Não criticando o código ARM -é um marcador de posição por enquanto.
{kind=link}