Problema de memoria con transmisión estructurada por chispa
Estoy enfrentando problemas de memoria al ejecutar una secuencia estructurada con agregación y particionamiento en Spark 2.2.0:
session
.readStream()
.schema(inputSchema)
.option(OPTION_KEY_DELIMITER, OPTION_VALUE_DELIMITER_TAB)
.option(OPTION_KEY_QUOTE, OPTION_VALUE_QUOTATION_OFF)
.csv("s3://test-bucket/input")
.as(Encoders.bean(TestRecord.class))
.flatMap(mf, Encoders.bean(TestRecord.class))
.dropDuplicates("testId", "testName")
.withColumn("year", functions.date_format(dataset.col("testTimestamp").cast(DataTypes.DateType), "YYYY"))
.writeStream()
.option("path", "s3://test-bucket/output")
.option("checkpointLocation", "s3://test-bucket/checkpoint")
.trigger(Trigger.ProcessingTime(60, TimeUnit.SECONDS))
.partitionBy("year")
.format("parquet")
.outputMode(OutputMode.Append())
.queryName("test-stream")
.start();
Durante las pruebas, noté que la cantidad de memoria utilizada aumenta cada vez que llegan nuevos datos y finalmente los ejecutores salen con el código 137:
ExecutorLostFailure (executor 2 exited caused by one of the running tasks) Reason: Container marked as failed: container_1520214726510_0001_01_000003 on host: ip-10-0-1-153.us-west-2.compute.internal. Exit status: 137. Diagnostics: Container killed on request. Exit code is 137
Container exited with a non-zero exit code 137
Killed by external signal
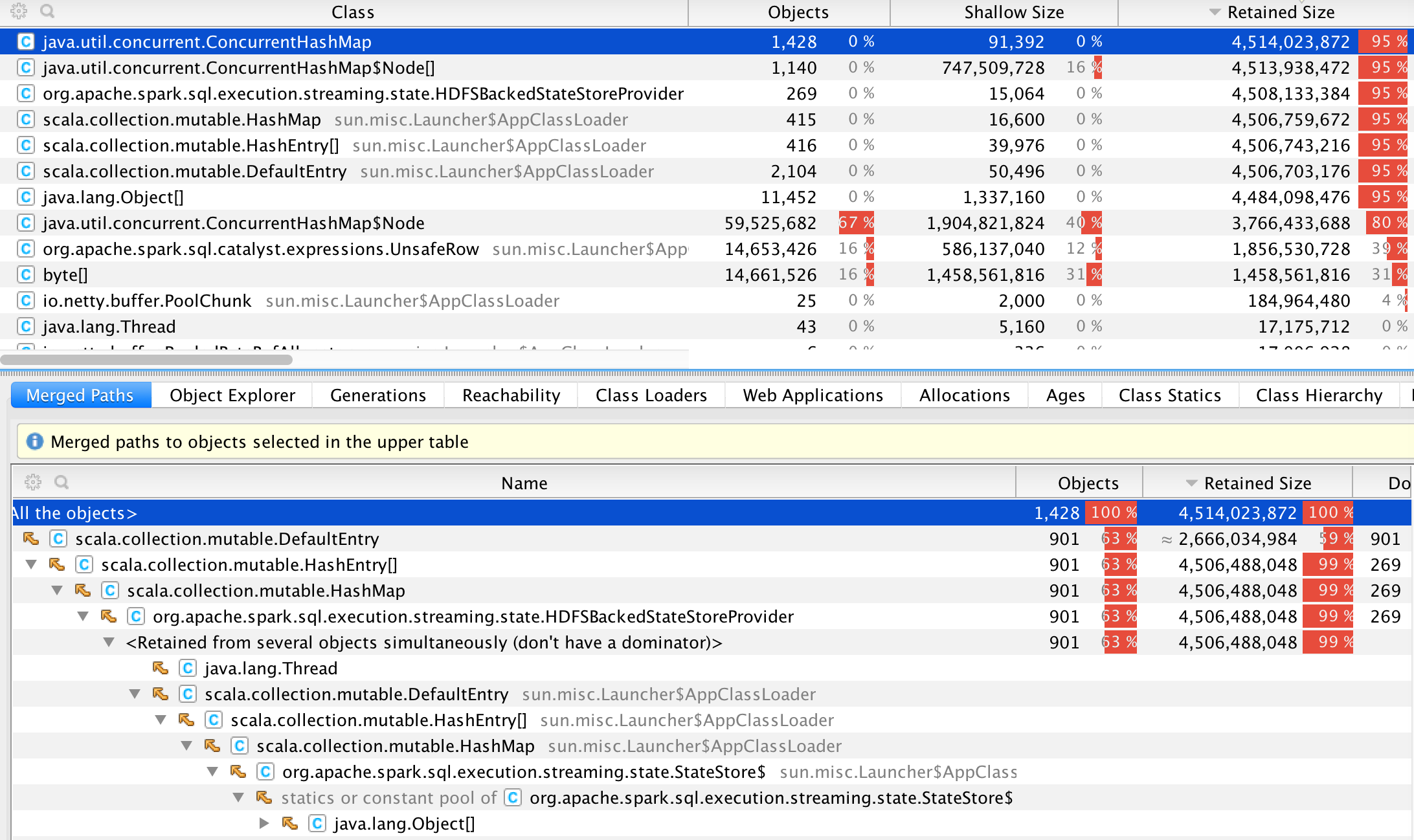
He creado un volcado de montón y descubrí que la mayor parte de la memoria utilizada pororg.apache.spark.sql.execution.streaming.state.HDFSBackedStateStoreProvider que se hace referencia desdeStateStore
A primera vista, parece normal, ya que así es como Spark mantiene las claves de agregación en la memoria. Sin embargo, realicé mis pruebas cambiando el nombre de los archivos en la carpeta de origen, para que pudieran ser recuperados por chispa. Dado que los registros de entrada son los mismos, todas las filas adicionales deben rechazarse como duplicados y el consumo de memoria no debe aumentar, pero lo es.
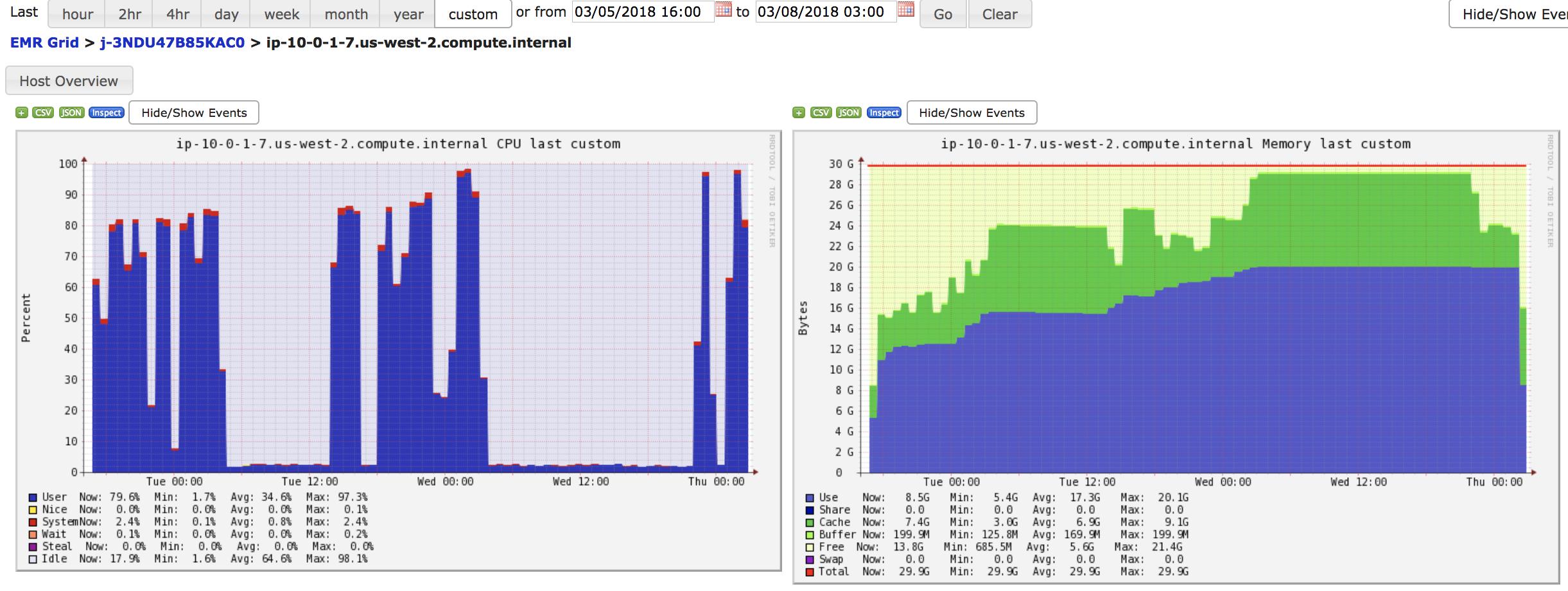
Además, el tiempo de GC tomó más del 30% del tiempo total de procesamiento

Aquí hay un volcado de montón tomado del ejecutor que se ejecuta con una menor cantidad de memoria que en las pantallas anteriores, ya que cuando estaba creando un volcado desde ese, el proceso de Java acababa de terminar en el medio del proceso.