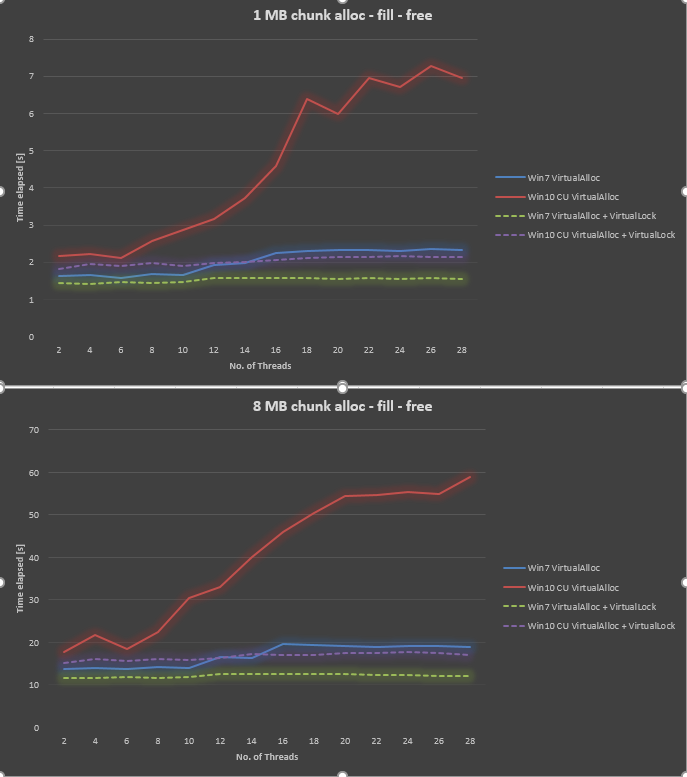
Windows 10 de bajo rendimiento en comparación con Windows 7 (el manejo de fallas de página no es escalable, contención de bloqueo severa cuando no hay hilos> 16)
Configuramos dos estaciones de trabajo HP Z840 idénticas con las siguientes especificaciones
2 x Xeon E5-2690 v4 @ 2.60GHz (Turbo Boost ON, HT OFF, total de 28 CPU lógicas)Memoria DDR4 2400 de 32 GB, cuatro canalese instaló Windows 7 SP1 (x64) y Windows 10 Creators Update (x64) en cada uno.
Luego ejecutamos un pequeño punto de referencia de memoria (código a continuación, construido con VS2015 Actualización 3, arquitectura de 64 bits) que realiza la asignación de memoria libre de relleno simultáneamente desde múltiples subprocesos.
#include <Windows.h>
#include <vector>
#include <ppl.h>
unsigned __int64 ZQueryPerformanceCounter()
{
unsigned __int64 c;
::QueryPerformanceCounter((LARGE_INTEGER *)&c);
return c;
}
unsigned __int64 ZQueryPerformanceFrequency()
{
unsigned __int64 c;
::QueryPerformanceFrequency((LARGE_INTEGER *)&c);
return c;
}
class CZPerfCounter {
public:
CZPerfCounter() : m_st(ZQueryPerformanceCounter()) {};
void reset() { m_st = ZQueryPerformanceCounter(); };
unsigned __int64 elapsedCount() { return ZQueryPerformanceCounter() - m_st; };
unsigned long elapsedMS() { return (unsigned long)(elapsedCount() * 1000 / m_freq); };
unsigned long elapsedMicroSec() { return (unsigned long)(elapsedCount() * 1000 * 1000 / m_freq); };
static unsigned __int64 frequency() { return m_freq; };
private:
unsigned __int64 m_st;
static unsigned __int64 m_freq;
};
unsigned __int64 CZPerfCounter::m_freq = ZQueryPerformanceFrequency();
int main(int argc, char ** argv)
{
SYSTEM_INFO sysinfo;
GetSystemInfo(&sysinfo);
int ncpu = sysinfo.dwNumberOfProcessors;
if (argc == 2) {
ncpu = atoi(argv[1]);
}
{
printf("No of threads %d\n", ncpu);
try {
concurrency::Scheduler::ResetDefaultSchedulerPolicy();
int min_threads = 1;
int max_threads = ncpu;
concurrency::SchedulerPolicy policy
(2 // two entries of policy settings
, concurrency::MinConcurrency, min_threads
, concurrency::MaxConcurrency, max_threads
);
concurrency::Scheduler::SetDefaultSchedulerPolicy(policy);
}
catch (concurrency::default_scheduler_exists &) {
printf("Cannot set concurrency runtime scheduler policy (Default scheduler already exists).\n");
}
static int cnt = 100;
static int num_fills = 1;
CZPerfCounter pcTotal;
// malloc/free
printf("malloc/free\n");
{
CZPerfCounter pc;
for (int i = 1 * 1024 * 1024; i <= 8 * 1024 * 1024; i *= 2) {
concurrency::parallel_for(0, 50, [i](size_t x) {
std::vector<void *> ptrs;
ptrs.reserve(cnt);
for (int n = 0; n < cnt; n++) {
auto p = malloc(i);
ptrs.emplace_back(p);
}
for (int x = 0; x < num_fills; x++) {
for (auto p : ptrs) {
memset(p, num_fills, i);
}
}
for (auto p : ptrs) {
free(p);
}
});
printf("size %4d MB, elapsed %8.2f s, \n", i / (1024 * 1024), pc.elapsedMS() / 1000.0);
pc.reset();
}
}
printf("\n");
printf("Total %6.2f s\n", pcTotal.elapsedMS() / 1000.0);
}
return 0;
}
Sorprendentemente, el resultado es muy malo en Windows 10 CU en comparación con Windows 7. Tracé el resultado a continuación para un tamaño de fragmento de 1 MB y un tamaño de fragmento de 8 MB, variando el número de subprocesos de 2,4, ..., hasta 28. Mientras que Windows 7 dio un rendimiento ligeramente peor cuando aumentamos el número de subprocesos, Windows 10 dio una escalabilidad mucho peor.

Hemos tratado de asegurarnos de que se apliquen todas las actualizaciones de Windows, actualizar los controladores, ajustar la configuración del BIOS, sin éxito. También ejecutamos el mismo punto de referencia en varias otras plataformas de hardware, y todas dieron una curva similar para Windows 10. Por lo tanto, parece ser un problema de Windows 10.
¿Alguien tiene una experiencia similar, o tal vez conocimientos sobre esto (tal vez nos perdimos algo?). Este comportamiento ha hecho que nuestra aplicación multiproceso tenga un impacto significativo en el rendimiento.
*** EDITADO
Utilizandohttps://github.com/google/UIforETW (gracias a Bruce Dawson) para analizar el punto de referencia, encontramos que la mayor parte del tiempo se pasa dentro de los núcleos KiPageFault. Excavando más abajo en el árbol de llamadas, todo conduce a ExpWaitForSpinLockExclusiveAndAcquire. Parece que la contención de bloqueo está causando este problema.

*** EDITADO
Datos recopilados de Server 2012 R2 en el mismo hardware. Server 2012 R2 también es peor que Win7, pero sigue siendo mucho mejor que Win10 CU.

*** EDITADO
Sucede también en Server 2016. Agregué la etiqueta windows-server-2016.
*** EDITADO
Usando información de @ Ext3h, modifiqué el punto de referencia para usar VirtualAlloc y VirtualLock. Puedo confirmar una mejora significativa en comparación con cuando VirtualLock no se usa. En general, Win10 sigue siendo 30% a 40% más lento que Win7 cuando ambos usan VirtualAlloc y VirtualLock.