¿Es más rápido iterar una pequeña lista dentro de una instrucción any ()?
Considere la siguiente operación en el límite de iterables de baja longitud,
d = (3, slice(None, None, None), slice(None, None, None))
In [215]: %timeit any([type(i) == slice for i in d])
1000000 loops, best of 3: 695 ns per loop
In [214]: %timeit any(type(i) == slice for i in d)
1000000 loops, best of 3: 929 ns per loop
Establecer como unlist es 25% más rápido que usar una expresión generadora?
¿Por qué es este el caso como una configuraciónlist Es una operación extra.
Nota: En ambas ejecuciones obtuve la advertencia:The slowest run took 6.42 times longer than the fastest. This could mean that an intermediate result is being cached I
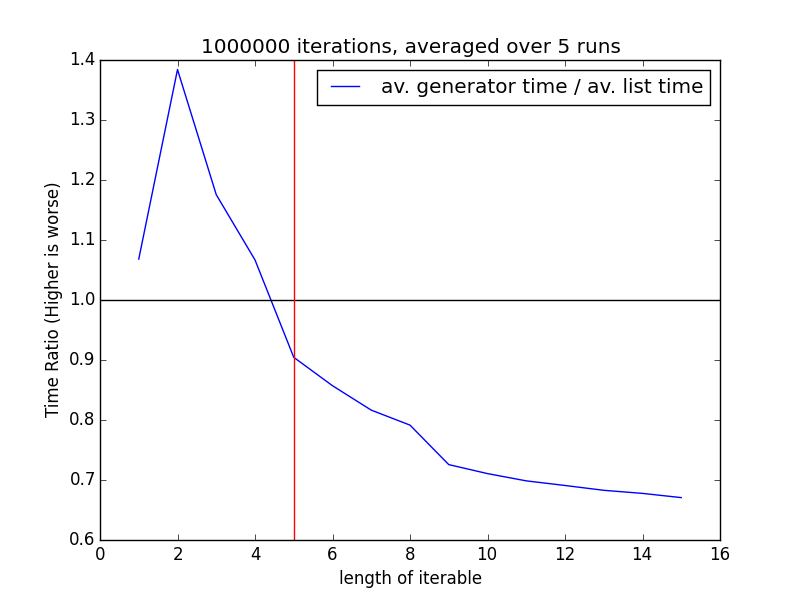
En esta prueba particular,list() las estructuras son más rápidas hasta una longitud de4 desde el cual el generador ha aumentado el rendimiento.
La línea roja muestra dónde ocurre este evento y la línea negra muestra dónde ambos son iguales en rendimiento.
import timeit, pylab, multiprocessing
import numpy as np
manager = multiprocessing.Manager()
g = manager.list([])
l = manager.list([])
rng = range(1,16) # list lengths
max_series = [3,slice(None, None, None)]*rng[-1] # alternate array types
series = [max_series[:n] for n in rng]
number, reps = 1000000, 5
def func_l(d):
l.append(timeit.repeat("any([type(i) == slice for i in {}])".format(d),repeat=reps, number=number))
print "done List, len:{}".format(len(d))
def func_g(d):
g.append(timeit.repeat("any(type(i) == slice for i in {})".format(d), repeat=reps, number=number))
print "done Generator, len:{}".format(len(d))
p = multiprocessing.Pool(processes=min(16,rng[-1])) # optimize for 16 processors
p.map(func_l, series) # pool list
p.map(func_g, series) # pool gens
ratio = np.asarray(g).mean(axis=1) / np.asarray(l).mean(axis=1)
pylab.plot(rng, ratio, label='av. generator time / av. list time')
pylab.title("{} iterations, averaged over {} runs".format(number,reps))
pylab.xlabel("length of iterable")
pylab.ylabel("Time Ratio (Higher is worse)")
pylab.legend()
lt_zero = np.argmax(ratio<1.)
pylab.axhline(y=1, color='k')
pylab.axvline(x=lt_zero+1, color='r')
pylab.ion() ; pylab.show()