Быстрый алгоритм для вычисления Пи параллельно
Я начинаю изучать CUDA, и я думаю, что вычисление длинных цифр числа пи было бы хорошим, вводным проектом.
Я уже реализовал простой метод Монте-Карло, который легко распараллеливать. Я просто заставляю каждый поток случайным образом генерировать точки на единичном квадрате, вычислять, сколько их лежит внутри единичного круга, и подсчитывать результаты, используя операцию сокращения.
Но это, конечно, не самый быстрый алгоритм для вычисления константы. Раньше, когда я делал это упражнение на однопоточном процессоре, я использовалМашиноподобные формулы сделать расчет для гораздо более быстрой сходимости. Для тех, кто заинтересован, это включает в себя выражение pi в виде суммы арктангенсов и использование рядов Тейлора для оценки выражения.
Пример такой формулы:
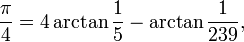
К сожалению, я обнаружил, что распараллелить эту технику с тысячами потоков GPU нелегко. Проблема состоит в том, что большинство операций просто выполняют математику с высокой точностью, а не операции с плавающей запятой над длинными векторами данных.
Так что мне интересно,what is the most efficient way to calculate arbitrarily long digits of pi on a GPU?