Я также копирую этот алгоритм, и у меня была та же ошибка, пока я не понял, что это проблема с тем, как я загружал данные. Выберите GMT при загрузке с Dukasopy вместо локального, тогда вы можете использовать его оригинальный код
ел указать формат даты, потому что она в европейском формате (иначе даты не будут в порядке после того, как я сделаю это в качестве столбца индекса). Я сделал именно из учебника следующим образом:
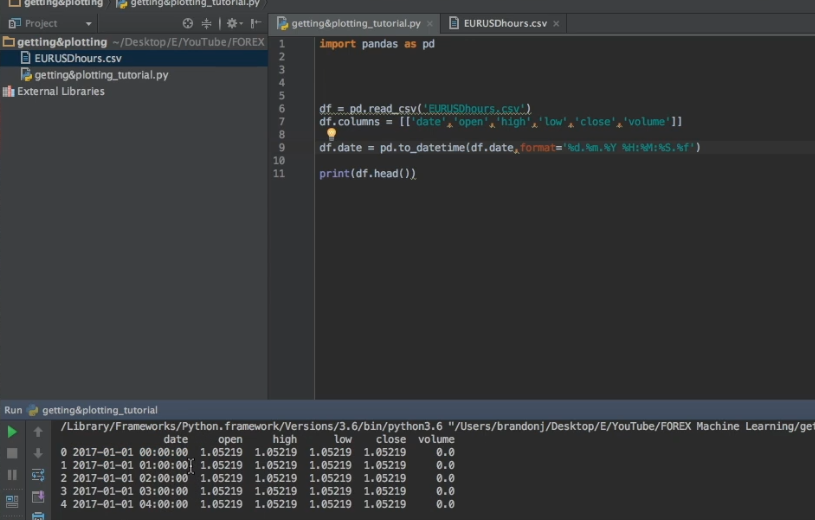
Но после того, как я выполню
df.date=pd.to_datetime(df.date,format='%d.%m.%Y %H:%M:%S.%f')
Я получаю эту ошибку
df = pd.read_csv("F:\Python\Jupyter notes\AUDCAD1h.csv")
df.columns = [['date', 'open','high','low','close','volume']]
df.head()
Out[66]:
date open high low close volume
0 01.01.2015 00:00:00.000 GMT-0500 0.94821 0.94821 0.94821 0.94821 0.0
1 01.01.2015 01:00:00.000 GMT-0500 0.94821 0.94821 0.94821 0.94821 0.0
2 01.01.2015 02:00:00.000 GMT-0500 0.94821 0.94821 0.94821 0.94821 0.0
3 01.01.2015 03:00:00.000 GMT-0500 0.94821 0.94821 0.94821 0.94821 0.0
4 01.01.2015 04:00:00.000 GMT-0500 0.94821 0.94821 0.94821 0.94821 0.0
df.Date=pd.to_datetime(df.date,format='%d.%m.%Y %H:%M:%S.%f')
Traceback (most recent call last):
File "<ipython-input-67-29b50fd32986>", line 1, in <module>
df.Date=pd.to_datetime(df.date,format='%d.%m.%Y %H:%M:%S.%f')
File "C:\Users\AM\Anaconda3\lib\site-packages\pandas\core\tools\datetimes.py", line 376, in to_datetime
result = _assemble_from_unit_mappings(arg, errors=errors)
File "C:\Users\AM\Anaconda3\lib\site-packages\pandas\core\tools\datetimes.py", line 446, in _assemble_from_unit_mappings
unit = {k: f(k) for k in arg.keys()}
File "C:\Users\AM\Anaconda3\lib\site-packages\pandas\core\tools\datetimes.py", line 446, in <dictcomp>
unit = {k: f(k) for k in arg.keys()}
File "C:\Users\AM\Anaconda3\lib\site-packages\pandas\core\tools\datetimes.py", line 441, in f
if value.lower() in _unit_map:
AttributeError: 'tuple' object has no attribute 'lower'
Почему я получил ошибку, но тот, за которым я следовал, не получил? Я точно скопировал код. Что с этим не так? Благодарю.