похоже, именно то, что вы предлагаете в своем ответе, верно?
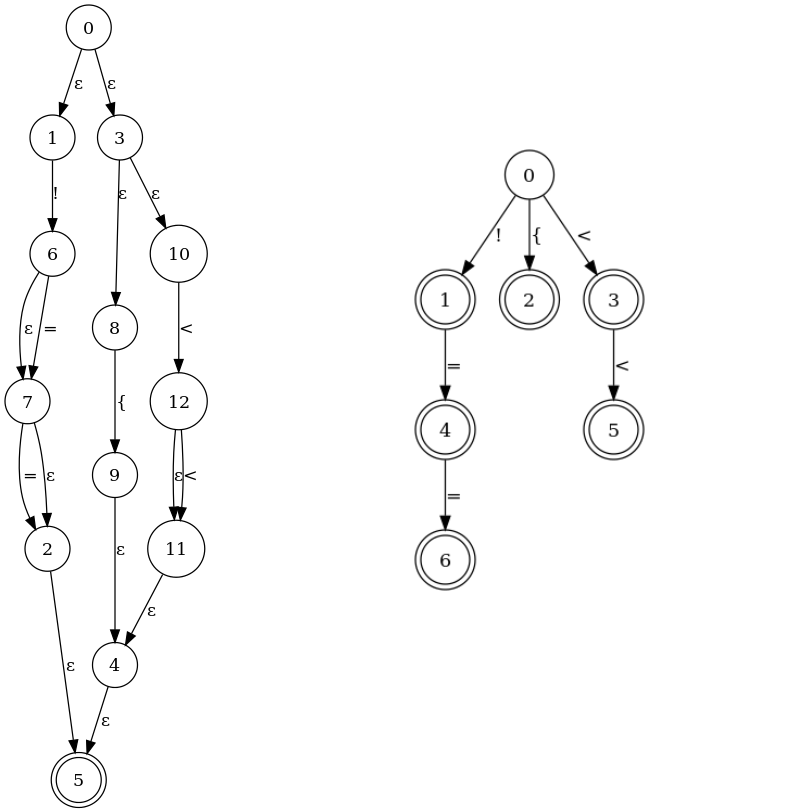
ою простой сканер. Предположим, у меня есть следующие токены, определенные для моего языка:
!, !=, !==, <, <<, {
Теперь я могу указать их с помощью регулярных выражений, поэтому:
!=?=? | { | <<?
Тогда я использовалhttp://hackingoff.com построить NFA и DFA. Теперь каждая машина может определить, введен ли ввод на языке регулярных выражений или нет. Но моя программа - это последовательность токенов, а не один токен:
!!=!<!==<<!{
Мой вопроскак я должен использовать машины для разбора строки в токены? Я заинтересован в подходе, а не в реализации.