Я использую geom_signif с ggsignif_0.4.0, а не ggpubr ... не могу изменить * размер ...
аюсь добавить уровни значимости к моемуприсущи рефлективный, вербальный в виде звездочек с помощьюggplot2 иggpubr пакет, но у меня есть много сравнений, и я хочу показать только важные из них.
Я пытаюсь использовать опциюhide.ns = TRUE, вstat_compare_means, но это понятноне работает, это может быть ошибка вggpubr пакет.
Кроме того, вы видите, что я исключаю группу "PGMC4" из парыwilcox.test сравнения; как я могу оставить эту группу также дляkruskal.test?
Последний вопрос, который у меня есть, как работает уровень значимости? Как в * значимо ниже 0,05, ** ниже 0,025, *** ниже 0,01? какое соглашение использует ggpubr? Это показывает p-значения или скорректированные p-значения? Если последнее, какой метод корректировки? BH?
Пожалуйста, проверьте мой MWE ниже иэта ссылка а такжеэтот другой для справки
##############################
##MWE
set.seed(5)
#test df
mydf <- data.frame(ID=paste(sample(LETTERS, 163, replace=TRUE), sample(1:1000, 163, replace=FALSE), sep=''),
Group=c(rep('C',10),rep('FH',10),rep('I',19),rep('IF',42),rep('NA',14),rep('NF',42),rep('NI',15),rep('NS',10),rep('PGMC4',1)),
Value=rnorm(n=163))
#I don't want to compare PGMC4 cause I have only onw sample
groups <- as.character(unique(mydf$Group[which(mydf$Group!="PGMC4")]))
#function to make combinations of groups without repeating pairs, and avoiding self-combinations
expand.grid.unique <- function(x, y, include.equals=FALSE){
x <- unique(x)
y <- unique(y)
g <- function(i){
z <- setdiff(y, x[seq_len(i-include.equals)])
if(length(z)) cbind(x[i], z, deparse.level=0)
}
do.call(rbind, lapply(seq_along(x), g))
}
#all pairs I want to compare
combs <- as.data.frame(expand.grid.unique(groups, groups), stringsAsFactors=FALSE)
head(combs)
my.comps <- as.data.frame(t(combs), stringsAsFactors=FALSE)
colnames(my.comps) <- NULL
rownames(my.comps) <- NULL
#pairs I want to compare in list format for stat_compare_means
my.comps <- as.list(my.comps)
head(my.comps)
pdf(file="test.pdf", height=20, width=25)
print(#or ggsave()
ggplot(mydf, aes(x=Group, y=Value, fill=Group)) + geom_boxplot() +
stat_summary(fun.y=mean, geom="point", shape=5, size=4) +
scale_fill_manual(values=myPal) +
ggtitle("TEST TITLE") +
theme(plot.title = element_text(size=30),
axis.text=element_text(size=12),
axis.text.x = element_text(angle=45, hjust=1),
axis.ticks = element_blank(),
axis.title=element_text(size=20,face="bold"),
legend.text=element_text(size=16)) +
stat_compare_means(comparisons=my.comps, method="wilcox.test", label="p.signif", size=14) + #WHY DOES hide.ns=TRUE NOT WORK??? WHY DOES size=14 NOT WORK???
stat_compare_means(method="kruskal.test", size=14) #GLOBAL COMPARISON ACROSS GROUPS (HOW TO LEAVE PGMC4 OUT OF THIS??)
)
dev.off()
##############################
MWE будет производить следующие боксы:
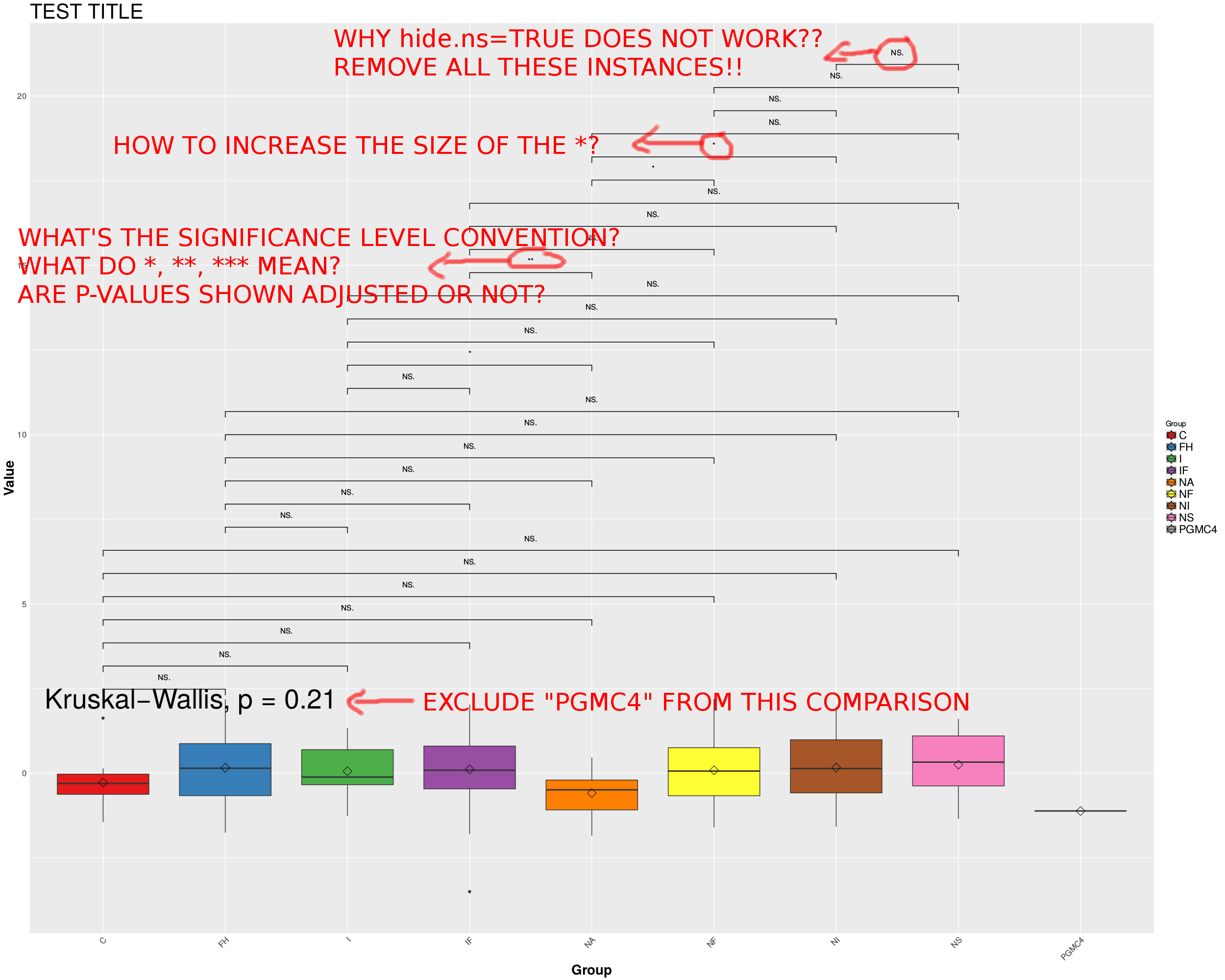
Вопросы будут:
1- Как заставить hide.ns = TRUE работать?
2- Как увеличить размер *?
3- Как исключить группу из сравнения kruskal.test?
4- Какое * соглашение используется ggpubr, и корректируются ли показанные p-значения или нет?
Большое спасибо!!
РЕДАКТИРОВАТЬ
Кроме того, при выполнении
stat_compare_means(comparisons=my.comps, method="wilcox.test", p.adjust.method="BH")
Я не получаю те же значения р, как при
wilcox.test(Value ~ Group, data=mydf.sub)$p.value
где mydf.sub является подмножеством () mydf для данного сравнения 2 групп.
Что здесь делает ggpubr? Как рассчитывается значение p.values?
РЕДАКТИРОВАТЬ 2
Пожалуйста, помогите, решение не должно быть с ggpubr (но это должно быть сggplot2), Мне просто нужно иметь возможность скрыть NS и сделать размер звездочек больше, а также вычислить значение p, идентичное wilcox.test () + p.adjust (метод "BH").
Спасибо!