Отличный ответ и интересная история для разработчиков, спасибо Фрэнк!
аюсь обдумать, как структурировать мои данные для базы данных реального времени Firebase. Я прочиталдокументы и некоторые другие вопросы о том, как найти следующие советы:
данные должны быть максимально плоскимибыть дорогим на записи, чтобы иметь дешевые чтенияизбегать вложенности данныхдублирование данных может быть хорошоИмея это в виду, позвольте мне описать мой конкретный вариант использования. Фрист естьпользователь со следующими атрибутами:
ИмяФамилияКартинка профиля (большая)Картинка профиля (маленькая)Пользователь может создать историю, которая состоит из следующих атрибутов:
пользовательТекстОтметкаВизуальное представление истории может выглядеть так:
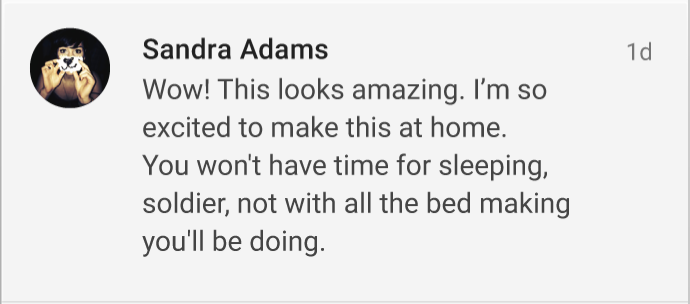
Мой вопрос: как бы вы связали информацию о пользователе (имя, фамилия, маленькая картинка профиля) с историей?
О чем я думал:
поместите user_id в историю, которая содержит внешний идентификатор для конкретного пользователя. Чтобы загрузить историю, нам нужно будет сделать два запроса к базе данных, один для получения истории, а другой для пользователя.
{user_id: 'XYZ', текст: 'foobar', отметка времени: ...}
введите имя, фамилию и небольшую фотографию в истории. Только один запрос будет необходим для отображения истории. Но мы должны были бы обновить историю каждого пользователя, когда, например, изображение профиля меняется.
{user_id: 'XYZ', имя: 'sandra', фамилия: 'adams', smallProfilePicutre: '...', текст: 'foobar', метка времени: ...}
Поэтому, когда создается несколько историй, и в большинстве случаев это просто чтение, подход 1. будет дорогостоящим, потому что мы платим за два чтения, чтобы отобразить историю. Подход 2. будет более экономически эффективным.
Я хотел бы здесь ваши мысли и идеи по этому поводу.