На пути к ограничению большого RDD
Я читаю много изображений, и я хотел бы поработать над небольшим их набором для разработки. В результате я пытаюсь понять, какискра а такжепитон может сделать это:
In [1]: d = sqlContext.read.parquet('foo')
In [2]: d.map(lambda x: x.photo_id).first()
Out[2]: u'28605'
In [3]: d.limit(1).map(lambda x: x.photo_id)
Out[3]: PythonRDD[31] at RDD at PythonRDD.scala:43
In [4]: d.limit(1).map(lambda x: x.photo_id).first()
// still running...
.. так что происходит? Я бы ожидалпредел () бежать намного быстрее, чем у нас было[2], но это не тот случай*.
Ниже я опишу свое понимание и, пожалуйста, поправьте меня, поскольку, очевидно, я что-то упускаю:
d это СДР пар (я знаю это из схемы), и я говорю с функцией карты:
я) Взять каждую пару (которая будет названаx и верни мнеphoto_id атрибуты).
II) Это приведет к новому (анонимному) RDD, в котором мы применяемfirst() метод, который я не уверен, как это работает$, но должен дать мне первый элемент этого анонимного RDD.
В[3]мы ограничиваемd СДР на 1, что означает, что, несмотря наd имеет много элементов, используйте только 1 и примените функцию map только к этому одному элементу.Out [3] должен быть RDD, созданным отображением.
[4]Я ожидал бы следовать логике[3] и просто распечатать единственный элемент ограниченного RDD ...Как и ожидалось, после просмотра монитора [4], кажется, обрабатываетвесь набор данныхв то время как другие нет, так что, похоже, я не используюlimit() правильно, или это не то, что я ищу:
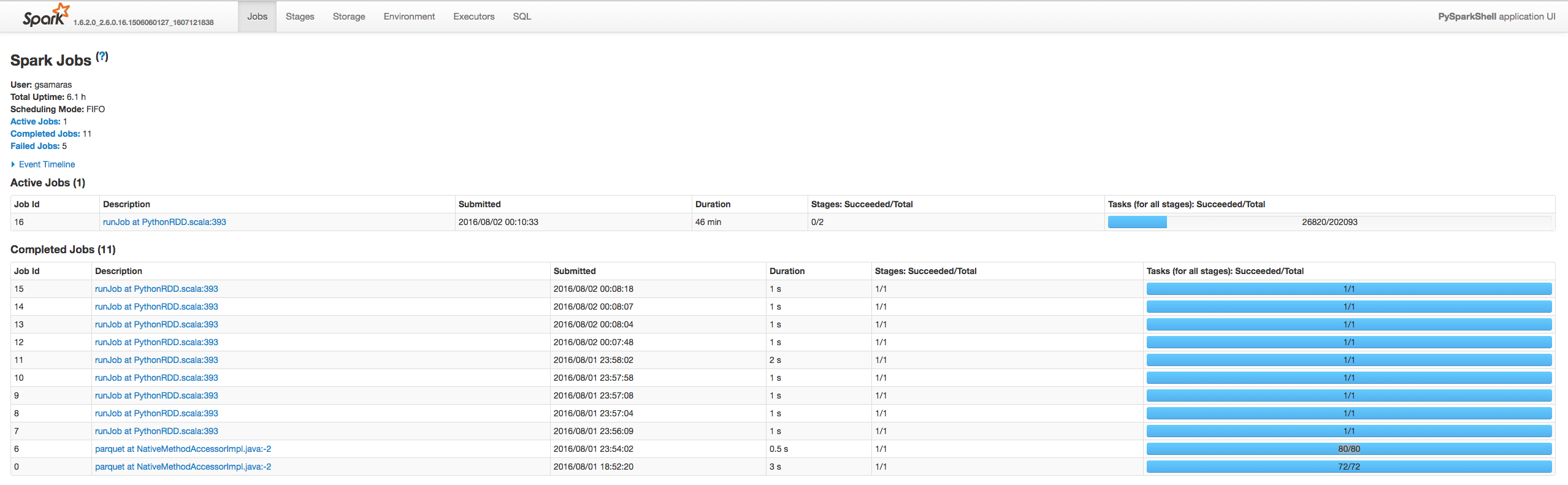
Редактировать:
tiny_d = d.limit(1).map(lambda x: x.photo_id)
tiny_d.map(lambda x: x.photo_id).first()
Первый дастPipelinedRDDкоторый, как описаноВот, это на самом деле не будет делатьдействиеПреображение.
Тем не менее, вторая строка также будет обрабатывать весь набор данных (на самом деле количество заданий теперь такое же, как и раньше, плюс одно!).
*[2] выполняется мгновенно, пока [4] еще работает и прошло> 3 часа ..
$Я не мог найти это в документации, из-за названия.