обработка параметров имени файла * с пробелами через RFC 5987 приводит к появлению '+' в именах файлов
У меня есть какой-то устаревший код, с которым я имею дело (поэтому я не могу просто использовать URL с закодированным компонентом имени файла), который позволяет пользователю загружать файл с нашего веб-сайта. Поскольку наши имена файлов часто бывают на разных языках, все они хранятся в формате UTF-8. Я написал некоторый код для обработки преобразования RFC5987 в правильный параметр имени файла *. Это прекрасно работает, пока у меня есть имя файла с не-ASCII символовand пространства. В соответствии с RFC символ пробела не является частью attr_char, поэтому он кодируется как% 20. У меня есть новые версии Chrome, а также Firefox, и все они конвертируются в% 20 + после загрузки. Я попытался не кодировать пространство и положить закодированное имя файла в кавычки и получить тот же результат. Я прослушал ответ от сервера, чтобы убедиться, что контейнер сервлета не перебивал мои заголовки, и они выглядят корректно для меня. В RFC даже есть примеры, содержащие% 20. Я что-то упустил или у всех этих браузеров есть ошибка, связанная с этим?
Спасибо заранее. Код, который я использую для кодирования имени файла, приведен ниже.
Питер
public static boolean bcsrch(final char[] chars, final char c) {
final int len = chars.length;
int base = 0;
int last = len - 1; /* Last element in table */
int p;
while (last >= base) {
p = base + ((last - base) >> 1);
if (c == chars[p])
return true; /* Key found */
else if (c < chars[p])
last = p - 1;
else
base = p + 1;
}
return false; /* Key not found */
}
public static String rfc5987_encode(final String s) {
final int len = s.length();
final StringBuilder sb = new StringBuilder(len << 1);
final char[] digits = {'0','1','2','3','4','5','6','7','8','9','A','B','C','D','E','F'};
final char[] attr_char = {'!','#','
Update
Вот снимок экрана диалога загрузки, который я получаю для файла с китайскими иероглифами с пробелами, как упомянуто в моем комментарии.
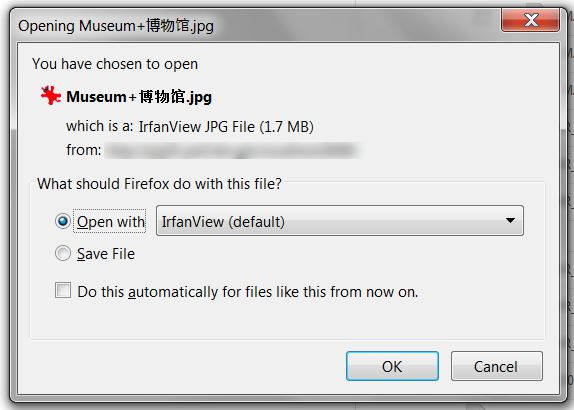
,'&','\'','+','-','.','0','1','2','3','4','5','6','7','8','9','A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z','^','_','a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z','|', '~'};
for (int i = 0; i < len; ++i) {
final char c = s.charAt(i);
if (bcsrch(attr_char, c))
sb.append(c);
else {
final char[] encoded = {'%', 0, 0};
encoded[1] = digits[0x0f & (c >>> 4)];
encoded[2] = digits[c & 0x0f];
sb.append(encoded);
}
}
return sb.toString();
}
Update
Вот снимок экрана диалога загрузки, который я получаю для файла с китайскими иероглифами с пробелами, как упомянуто в моем комментарии.