os pandas mesclam quadros de dados no timestamp mais próximo
Quero mesclar dois quadros de dados em três colunas: email, assunto e carimbo de data e hora. Os registros de data e hora entre os quadros de dados diferem e, portanto, preciso identificar o registro de data e hora mais próximo de um grupo de email e assunto.
Abaixo está um exemplo reproduzível usando uma função para a correspondência mais próxima sugerida paraesta Pergunta, questão.
import numpy as np
import pandas as pd
from pandas.io.parsers import StringIO
def find_closest_date(timepoint, time_series, add_time_delta_column=True):
# takes a pd.Timestamp() instance and a pd.Series with dates in it
# calcs the delta between `timepoint` and each date in `time_series`
# returns the closest date and optionally the number of days in its time delta
deltas = np.abs(time_series - timepoint)
idx_closest_date = np.argmin(deltas)
res = {"closest_date": time_series.ix[idx_closest_date]}
idx = ['closest_date']
if add_time_delta_column:
res["closest_delta"] = deltas[idx_closest_date]
idx.append('closest_delta')
return pd.Series(res, index=idx)
a = """timestamp,email,subject
2016-07-01 10:17:00,a@gmail.com,subject3
2016-07-01 02:01:02,a@gmail.com,welcome
2016-07-01 14:45:04,a@gmail.com,subject3
2016-07-01 08:14:02,a@gmail.com,subject2
2016-07-01 16:26:35,a@gmail.com,subject4
2016-07-01 10:17:00,b@gmail.com,subject3
2016-07-01 02:01:02,b@gmail.com,welcome
2016-07-01 14:45:04,b@gmail.com,subject3
2016-07-01 08:14:02,b@gmail.com,subject2
2016-07-01 16:26:35,b@gmail.com,subject4
"""
b = """timestamp,email,subject,clicks,var1
2016-07-01 02:01:14,a@gmail.com,welcome,1,1
2016-07-01 08:15:48,a@gmail.com,subject2,2,2
2016-07-01 10:17:39,a@gmail.com,subject3,1,7
2016-07-01 14:46:01,a@gmail.com,subject3,1,2
2016-07-01 16:27:28,a@gmail.com,subject4,1,2
2016-07-01 10:17:05,b@gmail.com,subject3,0,0
2016-07-01 02:01:03,b@gmail.com,welcome,0,0
2016-07-01 14:45:05,b@gmail.com,subject3,0,0
2016-07-01 08:16:00,b@gmail.com,subject2,0,0
2016-07-01 17:00:00,b@gmail.com,subject4,0,0
"""
Observe que para a@gmail.com o carimbo de data e hora correspondente mais próximo é 10:17:39, enquanto que para b@gmail.com a correspondência mais próxima é 10:17:05.
a = """timestamp,email,subject
2016-07-01 10:17:00,a@gmail.com,subject3
2016-07-01 10:17:00,b@gmail.com,subject3
"""
b = """timestamp,email,subject,clicks,var1
2016-07-01 10:17:39,a@gmail.com,subject3,1,7
2016-07-01 10:17:05,b@gmail.com,subject3,0,0
"""
df1 = pd.read_csv(StringIO(a), parse_dates=['timestamp'])
df2 = pd.read_csv(StringIO(b), parse_dates=['timestamp'])
df1[['closest', 'time_bt_x_and_y']] = df1.timestamp.apply(find_closest_date, args=[df2.timestamp])
df1
df3 = pd.merge(df1, df2, left_on=['email','subject','closest'], right_on=['email','subject','timestamp'],how='left')
df3
timestamp_x email subject closest time_bt_x_and_y timestamp_y clicks var1
2016-07-01 10:17:00 a@gmail.com subject3 2016-07-01 10:17:05 00:00:05 NaT NaN NaN
2016-07-01 02:01:02 a@gmail.com welcome 2016-07-01 02:01:03 00:00:01 NaT NaN NaN
2016-07-01 14:45:04 a@gmail.com subject3 2016-07-01 14:45:05 00:00:01 NaT NaN NaN
2016-07-01 08:14:02 a@gmail.com subject2 2016-07-01 08:15:48 00:01:46 2016-07-01 08:15:48 2.0 2.0
2016-07-01 16:26:35 a@gmail.com subject4 2016-07-01 16:27:28 00:00:53 2016-07-01 16:27:28 1.0 2.0
2016-07-01 10:17:00 b@gmail.com subject3 2016-07-01 10:17:05 00:00:05 2016-07-01 10:17:05 0.0 0.0
2016-07-01 02:01:02 b@gmail.com welcome 2016-07-01 02:01:03 00:00:01 2016-07-01 02:01:03 0.0 0.0
2016-07-01 14:45:04 b@gmail.com subject3 2016-07-01 14:45:05 00:00:01 2016-07-01 14:45:05 0.0 0.0
2016-07-01 08:14:02 b@gmail.com subject2 2016-07-01 08:15:48 00:01:46 NaT NaN NaN
2016-07-01 16:26:35 b@gmail.com subject4 2016-07-01 16:27:28 00:00:53 NaT NaN NaN
O resultado está errado, principalmente porque a data mais próxima está incorreta, pois não leva em consideração o email e o assunto.
O resultado esperado é
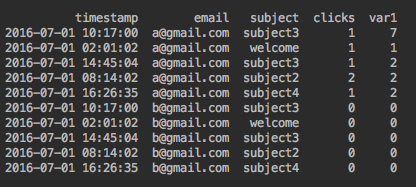{kind=link}
Alterar a função para fornecer os carimbos de data e hora mais próximos para um determinado email e assunto seria útil.
df1.groupby(['email','subject'])['timestamp'].apply(find_closest_date, args=[df1.timestamp])
Mas isso gera um erro, pois a função não está definida para um objeto de grupo. Qual é a melhor maneira de fazer isso?