Traçando os limites da zona de cluster no Python com o pacote scikit
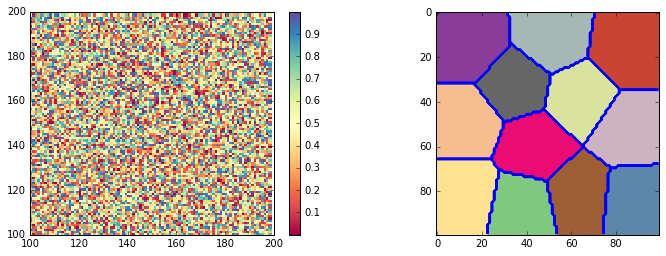
Aqui está meu exemplo simples de como lidar com o agrupamento de dados em 3 atributos (x, y, valor). cada amostra representa sua localização (x, y) e sua variável pertencente.
Meu código foi postado aqui:
x = np.arange(100,200,1)
y = np.arange(100,200,1)
value = np.random.random(100*100)
xx,yy = np.meshgrid(x,y)
xx = xx.reshape(100*100)
yy = yy.reshape(100*100)
j = np.dstack((xx,yy,value))[0,:,:]
fig = plt.figure(figsize =(12,4))
ax1 = plt.subplot(121)
xi,yi = np.meshgrid(x,y)
va = value.reshape(100,100)
pc = plt.pcolormesh(xi,yi,va,cmap = plt.cm.Spectral)
plt.colorbar(pc)
ax2 = plt.subplot(122)
y_pred = KMeans(n_clusters=12, random_state=random_state).fit_predict(j)
vb = y_pred.reshape(100,100)
plt.pcolormesh(xi,yi,vb,cmap = plt.cm.Accent)
A figura é apresentada aqui:
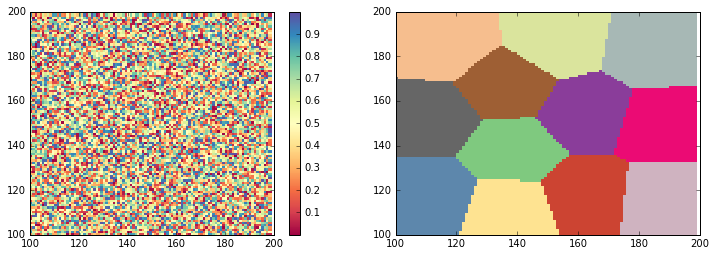
Como identificar os limites de cada zona de cluster e descrevê-los para intensificar o efeito de visualização.
PSAqui está uma ilustração que eu traço manualmente. Para identificar os limites do cluster e descrevê-los em linhas é o que eu preciso.
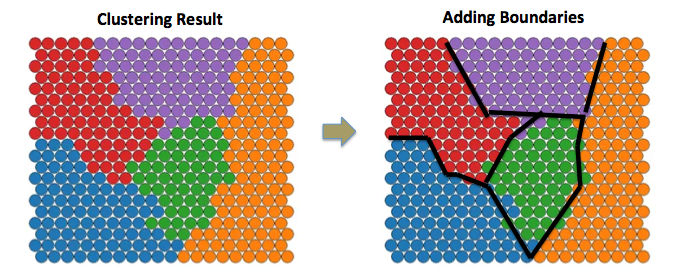
Eu achei uma pergunta interessanteaqui tentando traçar os limites da área de cluster emR
Depois de tentar, a sub-rotina a seguir:
for i in range(n_cluster):
plt.contour(vb ==i contours=1,colors=['b'])
Está feito!