Spark :: KMeans llama a takeSample () dos veces?
Tengo muchos datos y he experimentado con particiones de cardinalidad [20k, 200k +].
Yo lo llamo así:
from pyspark.mllib.clustering import KMeans, KMeansModel
C0 = KMeans.train(first, 8192, initializationMode='random', maxIterations=10, seed=None)
C0 = KMeans.train(second, 8192, initializationMode='random', maxIterations=10, seed=None)
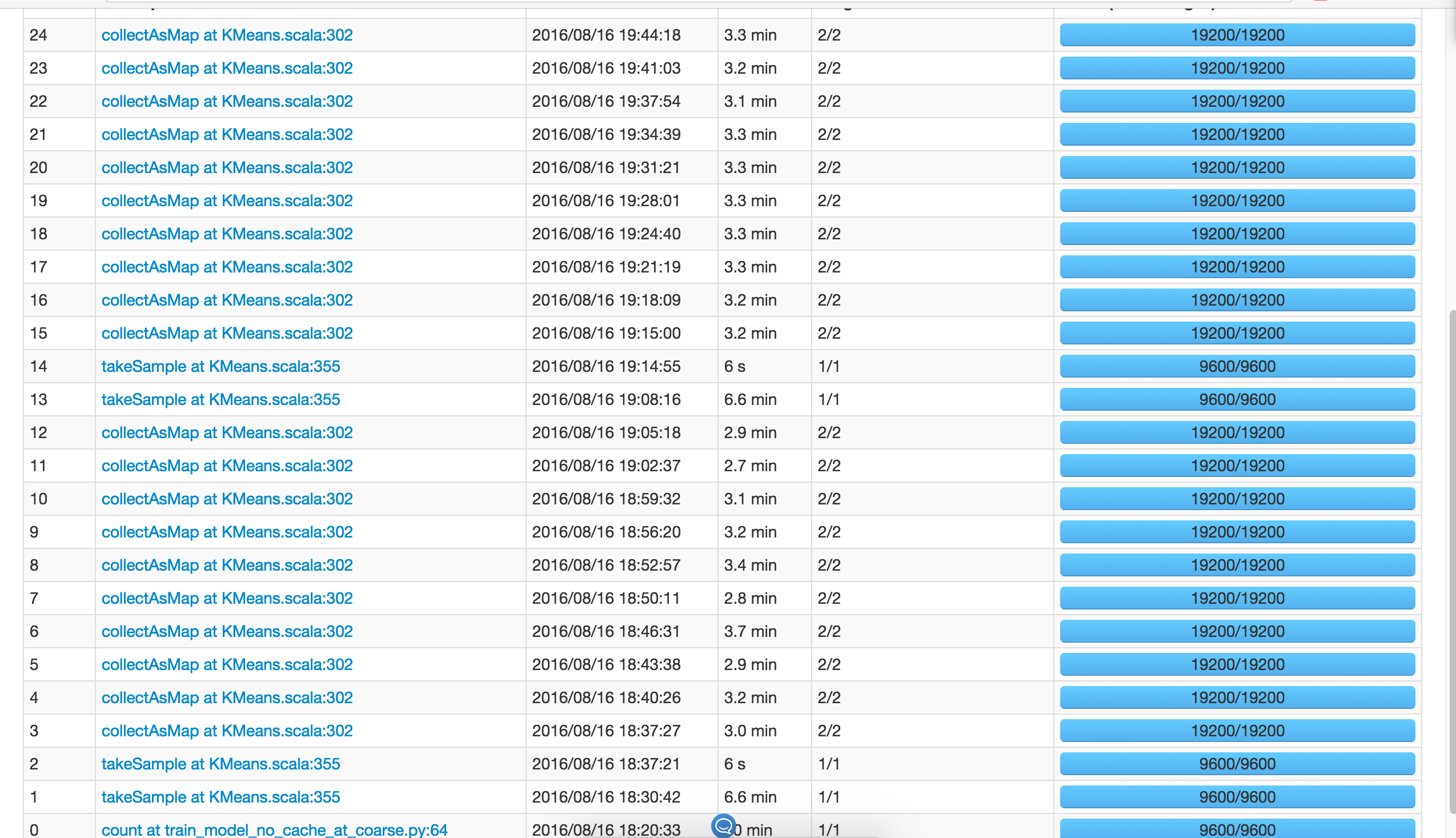
y veo queinitRandom () llamadastakeSample() una vez.
Entonces latakeSample () la implementación no parece llamarse a sí misma o algo así, así que esperaríaKMeans() llamartakeSample() una vez. Entonces, ¿por qué el monitor muestra dostakeSample()s perKMeans()?
{kind=link}
Nota: ejecuto másKMeans() y todos invocan dostakeSample()s, independientemente de los datos que se estén.cache()o no.
Además, el número de particiones no afecta el númerotakeSample() se llama, es constante a 2.
Estoy usando Spark 1.6.2 (y no puedo actualizar) y mi aplicación está en Python, si eso importa.
Lo traje a la lista de correo de los desarrolladores de Spark, así que estoy actualizando:
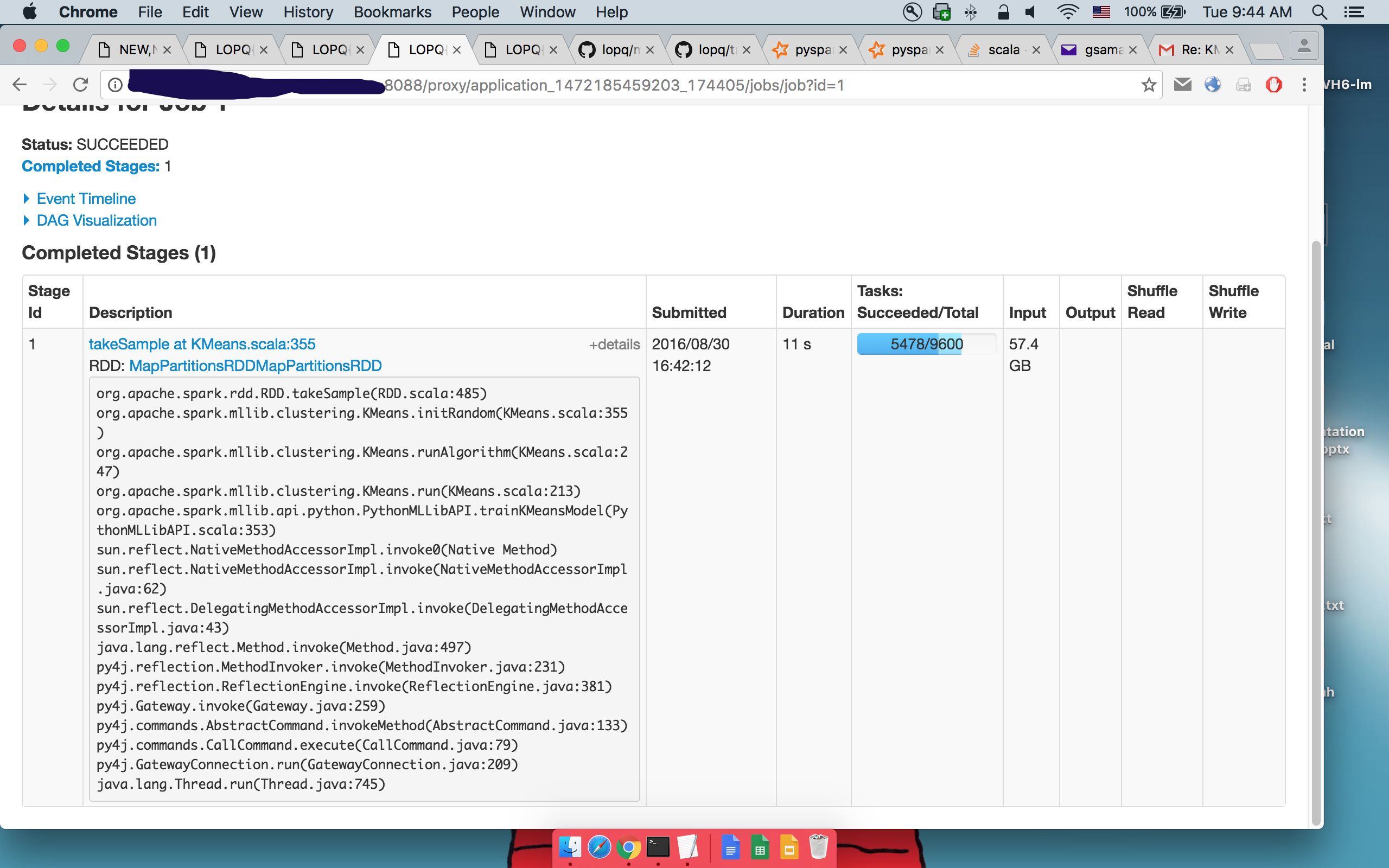
Detalles de 1ertakeSample():
{kind=link}
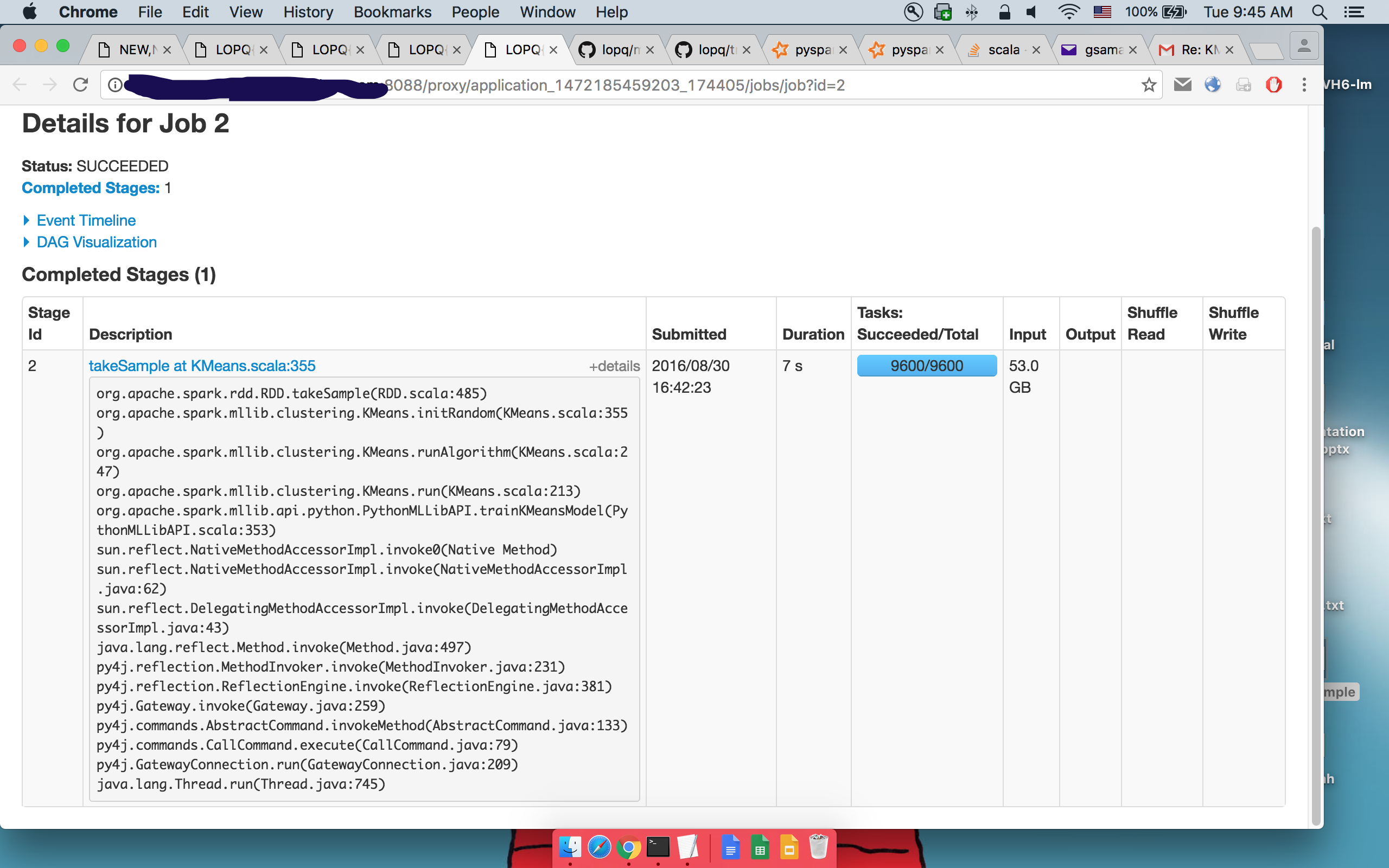
Detalles de 2dotakeSample():
{kind=link}
donde se puede ver que se ejecuta el mismo código.