Как сгруппировать близлежащие местоположения широты и долготы, хранящиеся в SQL
Я пытаюсь проанализировать данные об авариях на велосипеде в Великобритании, чтобы найти статистические черные пятна. Вот пример данных с другого сайта.http://www.cycleinjury.co.uk/map
В настоящее время я использую SQLite для хранения 100 000 латов. Я хочу сгруппировать близлежащие места вместе. Эта задача называетсякластерный анализ.
Я хотел бы упростить набор данных, игнорируя отдельные инциденты и вместо этого показывая только происхождение кластеров, в которых произошло более одного несчастного случая на небольшой территории.
Есть 3 проблемы, которые мне нужно преодолеть.
Спектакль - Как я могу найти ближайшие точки быстро. Должен ли я использоватьSQLite»реализация изR-Tree например?
Цепи - Как мне избежать цепей соседних точек?
плотность - Как принять во внимание плотность населения цикла? В Лондоне гораздо более высокая плотность велосипедистов, чем, скажем, в Бристоле, поэтому в Лондоне, похоже, больше шансов на помощь.
Я хотел бы избежатьцепь сценарии, подобные этому:
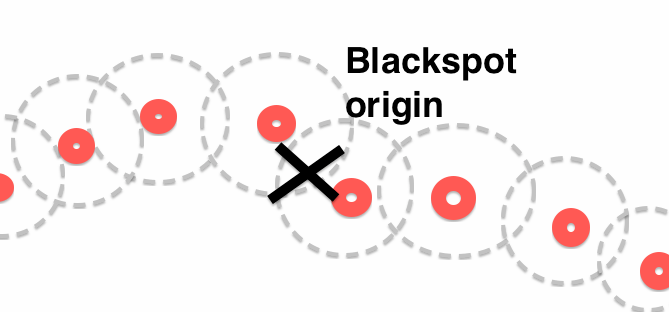
Вместо этого я хотел бы найти кластеры:

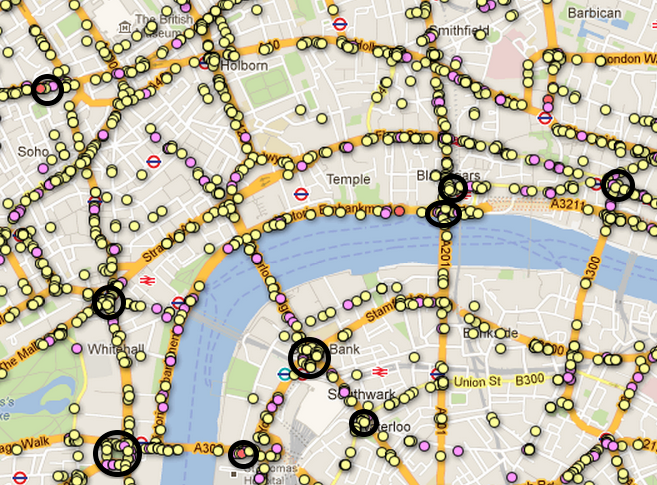
Скриншот Лондона (я нарисовал несколько кластеров) ...
Бристольский скриншот - гораздо более низкая плотность - та же программа, запущенная над этой областью, может не найти черных пятен, если не учитывать относительную плотность.

Любые указатели были бы великолепны!