Консольный вывод:
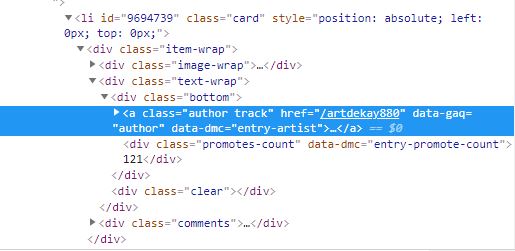
ние href для синего элемента - это то, к чему я хочу получить доступ из этого HTML
Я пробовал несколько способов напечатать ссылку, но ничего не вышло.
Мой код ниже: -
discover_page = BeautifulSoup(r.text, 'html.parser')
finding_accounts = discover_page.find_all("a", class_="author track")
print(len(finding_accounts))
finding_accounts = discover_page.find_all('a[class="author track"]')
print(len(finding_accounts))
accounts = discover_page.select('a', {'class': 'author track'})['href']
print(len(accounts))
Output:-
0
0
TypeError: 'dict' object is not callable
URL веб-страницыhttps://society6.com/discover но URL меняется наhttps://society6.com/society?show=2 после входа в мой аккаунт
Что я здесь не так делаю?
примечание: - Я использую браузер селена Chrome здесь. Ответ, данный здесь, работает в моем терминале, но не когда я запускаю файл
Мой полный код: -
from selenium import webdriver
import time
import requests
from bs4 import BeautifulSoup
import lxml
driver = webdriver.Chrome()
driver.get("https://society6.com/login?done=/")
username = driver.find_element_by_id('email')
username.send_keys("[email protected]")
password = driver.find_element_by_id('password')
password.send_keys("sultan1997")
driver.find_element_by_name('login').click()
time.sleep(5)
driver.find_element_by_link_text('My Society').click()
driver.find_element_by_link_text('Discover').click()
time.sleep(5)
r = requests.get(driver.current_url)
r.raise_for_status()
'''discover_page = BeautifulSoup(r.html.raw_html, 'html.parser')
finding_accounts = discover_page.find_all("a", class_="author track")
print(len(finding_accounts))
finding_accounts = discover_page.find_all('a[class="author track"]')
print(len(finding_accounts))
links = []
for a in discover_page.find_all('a', class_ = 'author track'):
links.append(a['href'])
#links.append(a.get('href'))
print(links)'''
#discover_page.find_all('a')
links = []
for a in discover_page.find_all("a", attrs = {"class": "author track"}):
links.append(a['href'])
#links.append(a.get('href'))
print(links)
#soup.find_all("a", attrs = {"class": "author track"})'''
soup = BeautifulSoup(r.content, "lxml")
a_tags = soup.find_all("a", attrs={"class": "author track"})
for a in soup.find_all('a',{'class':'author track'}):
print('https://society6.com'+a['href'])
коды в документации это тот, который я использовал, экспериментируя с